

In the race to solve complex problems with AI, the default strategy has become brute force: bigger models, more data, larger context windows. We put that assumption to the ultimate test on a critical healthcare task, and the results didn’t just challenge the “bigger is better” mantra; they shattered it. Here’s a preview of what our experiments uncovered:
Related FairPath Resources
- Out of the box, no leading LLM could break 9% accuracy. The top performer on our 1,150-term test achieved a jaw-dropping 8.43% on exact-match accuracy, while consistently inventing non-existent medical codes.
- Grok-4’s 1% accuracy is the most important result. While scoring a dismal 1.22% on exact matches, it demolished every other model on finding the right semantic neighborhood (44% accuracy), proving LLMs understand medical context but are structurally incapable of precision on their own.
- How to burn $18,000 proving the “large context” myth is a lie. A partner experiment that stuffed the entire SNOMED Disorders list into the prompt for every query wasn’t just wildly expensive — it was unstable, less accurate, and still produced hallucinations.
This is the precision problem, a challenge rooted in the messy reality of clinical language. A doctor jots down “AAA,” “abdo aneurysm,” or “aortic dilation” in a patient’s chart. A human clinician knows these all point to the same diagnosis: Abdominal Aortic Aneurysm . But for the computer systems processing this data, that human shorthand is a massive problem. To make sense of it all, modern healthcare relies on standardized ontologies like SNOMED CT — a vast, structured vocabulary that assigns a unique, canonical identifier to every diagnosis and procedure. Get this mapping right, and you unlock powerful analytics and safer patient care. Get it wrong, and you introduce costly errors.
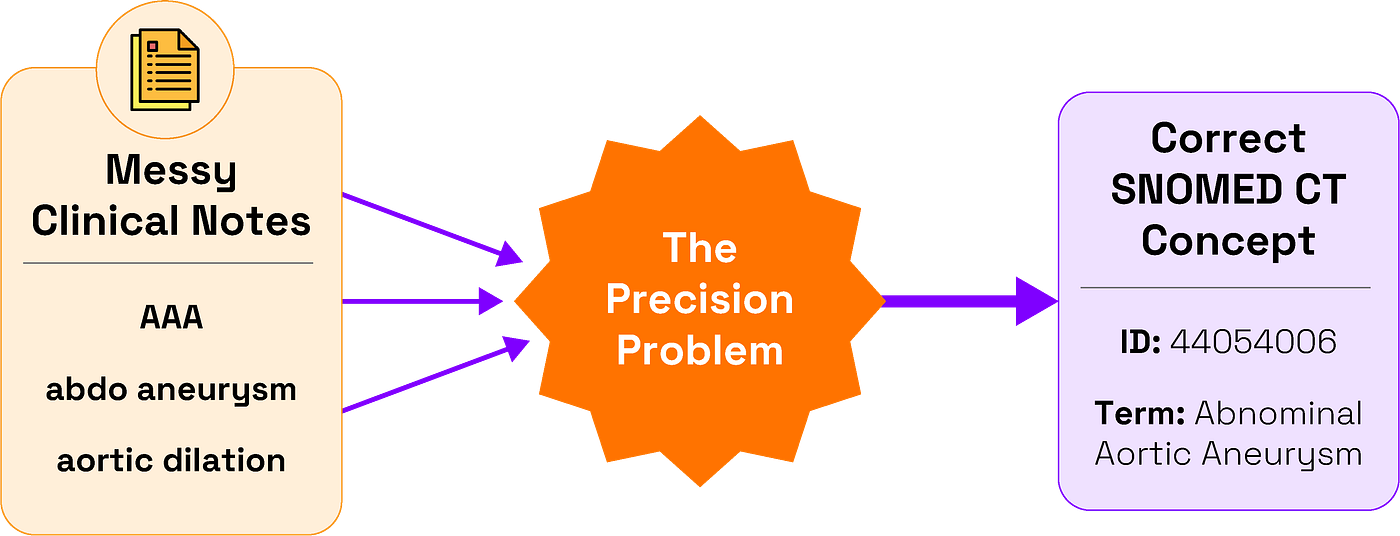
Unguided Large Language Models, as our results show, are not just ineffective for this task — they are fundamentally the wrong tool for the job. And solving it requires a new approach.
Enter Buffaly grounding and policy validation layer ( Buffaly ) . Instead of asking an LLM to recall a precise identifier from its vast, murky memory, Buffaly does something far more reliable: it gives the LLM a multiple-choice test.
The core idea is simple but powerful:
- Retrieve: First, use the ontology (our source of truth) to find a small, relevant list of valid candidate concepts for a given clinical term.
- Reason: Then, present this constrained list to the LLM and ask it to use its powerful reasoning abilities to select the best option.
- Validate: Finally, confirm the LLM’s choice against the ontology’s rules.
This approach combines the best of both worlds: the structured, verifiable authority of an ontology and the flexible, contextual understanding of an LLM. It constrains the model’s decision-making space, effectively eliminating hallucinations and forcing it to choose from a set of known-good answers.
In this article, we’ll walk you through the experiments that prove this method works. Using a dataset of over 1,150 clinical tags provided by our collaborator,
Dr. Tisloh Danboyi (UK)
, we’ll show you the hard data comparing naïve approaches, pure LLMs, and three progressively powerful levels of Buffaly. You’ll see exactly how grounding an LLM transforms it from an unreliable guesser into a precise, trustworthy reasoning engine — a pattern that holds promise far beyond just SNOMED mapping.
The Buffaly Framework: A “Multiple-Choice Test” for LLMs
The catastrophic failure of unguided LLMs reveals a core truth: asking a model to recall a precise, canonical identifier is like giving it an open-ended essay question when what you need is a single, verifiable fact. The model will give you a beautifully written, contextually aware, and often completely wrong answer.
Buffaly grounding and policy validation layer fixes this by changing the nature of the test. Instead of an essay, we give the LLM a multiple-choice exam where the ontology provides the only valid answers. The LLM’s job is no longer to recall but to reason and select .
At its heart, Buffaly is a simple, reusable pattern. It equips an LLM with a minimal set of “tools” that allow it to interact with a structured knowledge base (like SNOMED CT). These tools are not complex; they are basic functions:
- Search Tool: Finds candidate concepts based on an input term.
- Neighborhood Tool: Explores related concepts (parents, children, siblings) to add context.
- Validation Tool: Confirms if a chosen concept is valid according to ontology rules.
- Canonicalization Tool: Formats the final choice into a standard ID and label.
The power of Buffaly is its flexibility. It’s not a single, rigid method but a spectrum of implementations that trade human oversight for automation. We tested three distinct levels.
Level 1: The Human-in-the-Loop Selector
At its simplest, Buffaly acts as a safeguard. A human analyst (or a simple script) performs a basic search against the ontology to retrieve a list of plausible candidates. The LLM is then given one, highly constrained job: choose the best option from this pre-approved list.
Think of this as handing the LLM a curated list of answers. It can’t hallucinate because it can’t write in its own response. This approach is ideal for initial validation or for workflows where human oversight is paramount. It’s safe, low-cost, and immediately eliminates the risk of fabricated codes.
Level 2: The Creative Query Expander
What if the correct term isn’t found in the initial search? This is where clinician shorthand gets tricky. Level 2 leverages the LLM’s linguistic creativity to solve this recall problem.
Instead of asking the LLM to choose a final answer, we ask it to brainstorm alternate phrasings . Given the term “heart failure with preserved EF,” the LLM might generate a list of synonyms clinicians actually use:
- “HFpEF”
- “diastolic heart failure”
- “heart failure normal ejection fraction”
We then run
exact searches
on these LLM-generated strings. The LLM never outputs a code; it only provides better search terms. This dramatically increases the chances of finding the right concept, bridging the gap between clinical slang and formal ontology descriptions.
Level 3: The Autonomous Agent
This is Buffaly in its most advanced form. Here, the LLM becomes an autonomous agent, equipped with the ontology tools and a clear goal: “Map this term to the correct SNOMED concept.” The agent then works through a reason-act loop:
- Search for initial candidates.
- Analyze the results. Are they good enough?
- If unsure, Navigate the ontology’s hierarchy (check parent or child concepts) to refine its understanding.
- Validate its final candidate against ontology rules.
- Decide on a final answer or, crucially, choose to safely abstain if confidence is low.
Picture an expert researcher navigating a library’s card catalog, pulling related files, and cross-referencing until they find the exact document they need. The agentic approach is perfect for high-volume, automated workflows where you need both high accuracy and the intelligence to know when to stop.

Ultimately, Buffaly is a flexible framework. You can choose the level of autonomy that fits your needs, but the guiding principle remains the same: by grounding the LLM’s powerful reasoning within the strict, verifiable boundaries of an ontology, you get the best of both worlds — intelligent understanding and certifiable precision.
The Crucible: Experimental Design and Results
A framework is only as good as the evidence that supports it. To prove Buffaly’s effectiveness, we designed a rigorous, head-to-head comparison against the most common approaches to this problem. Our goal was to create a fair, reproducible test that would show, with hard numbers, what really works.
Part 1: The Setup
Before diving into the results, it’s crucial to understand the components of our experiment: the raw data, the technical implementation of our knowledge base, and the metrics we used to define success.
The Dataset: Real-World Clinical Messiness
We didn’t use clean, synthetic data. Our testbed was the Health Tags Dataset , a collection of approximately 1,150 real-world clinical terms graciously provided by Dr. Tisloh Danboyi (UK). This dataset is a true representation of the challenge, filled with the messy, abbreviated, and sometimes misspelled shorthand that clinicians actually use.
To ensure fair and objective scoring, we manually curated a “golden set” — a definitive answer key containing the correct SNOMED CT mapping for every single term in the dataset. Recognizing that clinical language can be ambiguous, our curation process involved multiple reviewers. A concept was only included in the golden set as a possible correct answer if at least two independent reviewers agreed on its validity. During this process, we always prioritized the most specific and precise SNOMED concept available that accurately captured the term’s meaning.
The Ontology: A Programmable Knowledge Graph
Treating a vast ontology like SNOMED CT as a static file would be slow and inefficient. Instead, we implemented it as a ProtoScript-based programmable ontology . This transformed SNOMED from a simple dictionary into a dynamic, in-memory knowledge graph that our tools and agents could interact with efficiently. This approach was critical, enabling the high-speed semantic navigation and validation required for the Level 3 agent.
The Scorecard: Defining Success
We graded every prediction against our golden set using two distinct metrics designed to measure both perfect precision and general recall.
- Strict Accuracy (Exact Set Match): This is the gold standard for clinical-grade precision. A prediction was scored as correct only if the set of predicted SNOMED CT concept IDs was identical to the set of correct IDs in our golden set for that term. This is a measure of perfect precision and recall; any extra, missing, or incorrect predictions for a given term resulted in a score of zero.
- Lenient Accuracy (Overlap Match): This more forgiving metric measures a method’s ability to retrieve any relevant information. A prediction was scored as correct if there was at least one overlapping concept ID between the predicted set and the golden set. This score does not penalize for extra, incorrect predictions and is invaluable for understanding a method’s raw recall — its ability to find a signal, even if it’s surrounded by noise.
With the methodology established, we first set out to prove why a new approach was needed by testing the baselines.
Part 2: Establishing the Baseline: Why Common Approaches Fail
Before demonstrating Buffaly, we had to prove why a new approach was necessary. We established three baselines representing the most common strategies: a simple lexical search, unguided LLMs, and a brute-force large context prompt. All three failed, but they failed in uniquely instructive ways.
Baseline 1: The Brittle 50/50 Shot of Lexical Search
First, we established a non-AI baseline to represent the classical approach used before advanced retrieval became common. The method is intentionally simple and deterministic: for each clinical term, we performed a direct search across SNOMED’s official descriptions ( Preferred Term , Fully Specified Name , and Synonyms ). The very first match found was immediately accepted as the correct one.
This approach is extremely fast and has no external dependencies, but its limitations are severe:
- It is highly sensitive to even minor spelling differences, abbreviations, and morphological changes.
- It completely misses synonyms or clinical expressions not explicitly listed in SNOMED.
- It has no capacity to handle ambiguity or nuanced context.
Results:
- Correct: 620
- Incorrect: 530
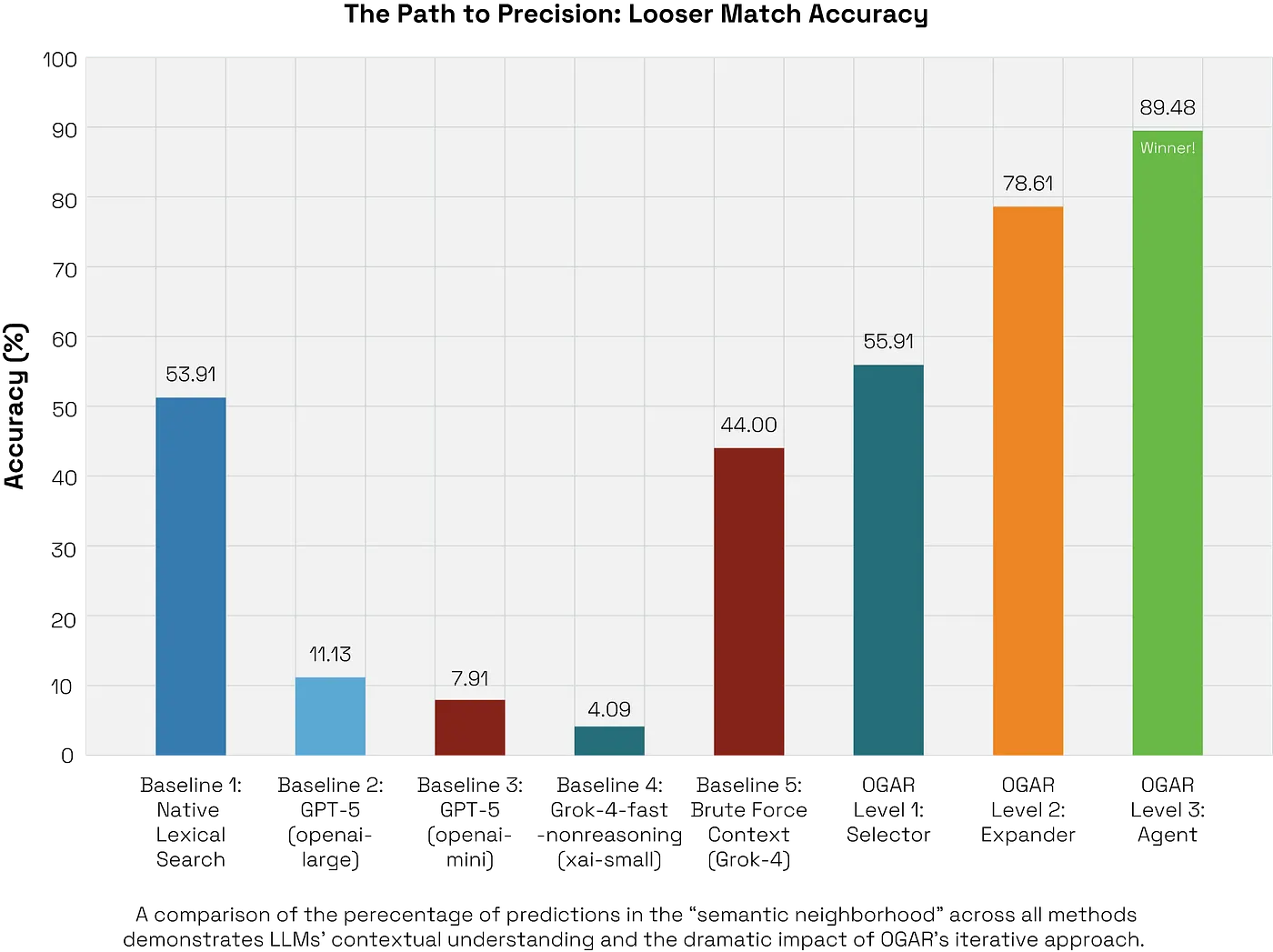
- Exact Match Accuracy: 53.91%
What this tells us:
This simple method is essentially a coin flip. It successfully captures about half of the dataset, but only the “easy” cases — standardized phrases that appear verbatim in SNOMED’s official descriptions. The 530 misses are a clear map of real-world clinical language: abbreviations, spelling variants, and paraphrases that clinicians use every day but that formal ontologies don’t list.
This gives us a strong, zero-cost baseline. It defines the wall that any intelligent system must overcome: the roughly 50% of clinical language that requires more than a simple lookup. It sets the stage for Buffaly, which is designed to recover these 530 errors without resorting to handcrafted rules.
Baseline 2: The Catastrophic Failure of Unguided LLMs
Next, we tested the “memory-only” hypothesis that a sufficiently advanced LLM could simply recall the correct SNOMED ID. We prompted four leading models with a simple, direct request for each of the 1,150 terms:
“Provide the SNOMED CT concept ID and preferred term for the condition [term].”
There were no tools, no retrieval, and no ontology provided in the context. The result was a total system failure.
Per-Model Results
The data shows a consistent and profound inability to perform this task.
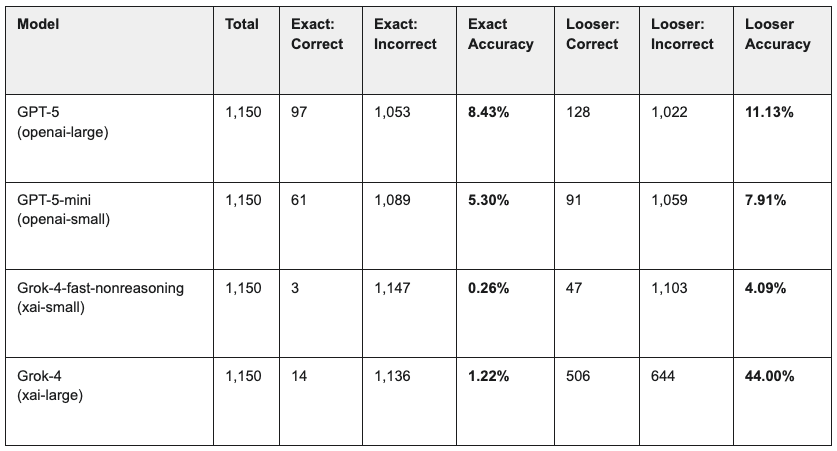
The aggregate performance across all 4,600 predictions was just 3.80% exact accuracy , with a median of 3.26% .
What this tells us:
- ID Recall is Unusable and Hallucinations are Rampant. Even the best-performing model, GPT-5, achieved a jaw-droppingly low 8.43% accuracy. More critically, the models frequently produced non-existent, fabricated IDs and non-standard descriptions. This isn’t just a failure of accuracy; it’s a failure of safety.
- The Grok-4 Paradox: Semantic Understanding without Precision. The most fascinating result came from Grok-4. While scoring a near-zero 1.22% on exact matches , it achieved a remarkable 44.00% on the looser score .
-
Bigger Models Don’t Fix a Structural Flaw.
Scaling from a “mini” model to a large one did not close the gap. The failure is architectural, not a matter of scale. Without a bounded answer space or a versioned reference to check against, the model is simply guessing.
The Grok-4 Paradox: A Strategy of “Going Wide” vs. “Going Narrow”
The most fascinating result came from Grok-4. While scoring a near-zero 1.22% on Strict Accuracy , it achieved a remarkable 44.00% on Lenient Accuracy . This isn’t an anomaly; it reflects a fundamental difference in model strategy.
Grok’s approach appears to be to “go wide” — it returns a broader set of potential answers for a given query. In contrast, models like GPT tend to “go narrow,” often providing only a single, highly confident guess.
This strategic choice directly explains the score discrepancy. By going wide, Grok is far more likely to include at least one correct concept in its output, dramatically boosting its Lenient Accuracy . However, that same output is often cluttered with hallucinated answers, guaranteeing failure on our Strict Accuracy metric, which requires a perfect set with no extras.
This is the smoking gun: it proves the model understands the semantic context of clinical language but is structurally incapable of pinpointing the precise, canonical identifier. It can find the right neighborhood, but it can’t find the right address. Its strategy ensures the correct answer is often somewhere in the pile, but it’s buried in noise.
Conclusion on this Baseline:
The takeaway is unequivocal: a production-grade clinical mapper
cannot
rely on an LLM’s memory. Pure, unguided generation yields clinically unacceptable accuracy and rampant identifier fabrication. This baseline proves that to have any chance of success, we must introduce an external source of truth and fundamentally constrain the model’s decision-making process.
Baseline 3: The $18,000 Fallacy of Brute-Force Context
Debunking the Myth that “More Context” Is Always Better
Having seen that LLMs fail without grounding, we analyzed a control experiment that tested the most common brute-force solution: what if you just give the model all the possible answers in the prompt?
Before adopting Buffaly’s targeted retrieval, our UK partner, Dr. Tisloh Danboyi, ran this exact test. The idea was to try the most direct thing imaginable: for each query, send a single clinical term along with the entire SNOMED Disorders file and ask the model to pick the right one. No tools, no clever retrieval — just a massive data dump.
How It Was Set Up
For each clinical term, the prompt bundled:
- The term itself (e.g., “AAA”).
- The full Disorders CSV file, containing approximately 143,025 distinct entries.
The model was explicitly instructed to choose the correct concept and label from the provided in-prompt file. Preliminary runs were so token-heavy (consuming about 850,000 input tokens per term ) that projecting the cost for our full dataset, even with a low-cost model like GPT-4o-mini, implied a bill of ≈$18,235 in input fees alone , before any validation or reruns.
What Happened: A Lesson in Futility
The experiment wasn’t just economically insane; it was a technical failure.
- Attention Overload and Instability. Drowning the model in a 143,000-entry list resulted in classic long-context saturation. Its selections were inconsistent, with identical inputs sometimes yielding different outputs across runs. The model couldn’t reliably maintain its focus across the massive, undifferentiated context.
- It Still Hallucinated. This was the most critical finding. Despite being shown the official list of correct answers, the model still occasionally returned non-existent or non-standard IDs and labels. This is a powerful reminder that simply exposing a model to the truth does not enforce a constraint to use it.
- Poor Economics. The vast majority of the token cost was for static, repeated ontology text, not for active reasoning. As the context ballooned, accuracy on nuanced terms actually fell while the cost rose steeply, making the entire approach impractical at scale.
Takeaway: Context is Not a Substitute for Constraints
This experiment serves as a powerful cautionary tale. Stuffing the entire ontology into a prompt for every query is neither reliable nor economical . The model struggles to reason effectively over massive, noisy contexts and remains free to fabricate when not explicitly constrained.
This failure is precisely why we moved to Buffaly. Instead of drowning the model in the entire ocean of the ontology, Buffaly intelligently retrieves just the relevant, targeted slice. It then asks the model to reason within that small, bounded set and validates the outcome. This delivers superior accuracy, stability, and sane costs — proving that for precision tasks, a well-defined boundary is far more valuable than a massive context window.
Part 3: The Buffaly Progression: From Simple Safeguards to Autonomous Success
Having established a clear picture of what doesn’t work — brittle lexical searches, hallucinatory unguided LLMs, and unstable brute-force prompts — we turned to the Buffaly framework. Instead of a single method, we tested three progressively sophisticated implementations. Each level introduces more automation and autonomy, systematically addressing the failures of the baselines and demonstrating how combining LLM reasoning with ontological tools unlocks dramatic performance gains.
Buffaly Level 1: The Safety Net & Smarter Adjudicator
We began with the most minimal implementation of Buffaly possible. The goal here was not to achieve maximum accuracy, but to solve the most dangerous problem first — hallucinations — and to isolate the value of LLM reasoning on a fixed set of candidates.
What We Ran
The process was intentionally simple, using the exact same retrieval method as our first baseline.
- Retrieve: For each term, we ran a basic substring search against the ontology’s descriptions (Preferred Term, FSN, Synonyms) to get a list of candidate concepts.
- Reason: We then passed that bounded list to a small LLM and asked it to pick the best one, rather than just blindly taking the first result.
Results
- Exact Match: 638 correct, 512 incorrect → 55.48% accuracy
- Looser Score: 643 correct, 507 incorrect → 55.91% accuracy
- Hallucinations: None. By construction, the model can only choose from valid, ontology-provided candidates.
Analysis
This result reveals a subtle but important finding. The value of Buffaly Level 1 is twofold and significant:
- It Provides a Perfect Safety Net. First and foremost, the “multiple-choice” constraint completely solves the hallucination problem from Baseline 2. This single design choice makes the system fundamentally trustworthy from the start.
- An LLM is a Smarter Adjudicator. Compared to the naïve non-AI baseline (53.91%), we see a modest but real gain of +1.57 points in exact accuracy, finding 18 more correct matches . Where did these come from? The baseline’s “first hit wins” rule is brittle. If a search returned a list like [Incorrect Match, Correct Match], the baseline failed. Buffaly Level 1, however, gave this entire list to the LLM. The LLM used its superior reasoning to look past the first noisy result and correctly select the right answer, rescuing it from the candidate list.
This improved adjudication is also reflected in the looser score, which saw a +4.69 point gain over the baseline. This confirms that even when the exact match isn’t available, the LLM is better at identifying the most semantically relevant option in the candidate pool. This level proves that while constraints solve for safety, the LLM’s reasoning provides a tangible, measurable improvement in precision, even on a poor candidate list. It powerfully sets the stage for Level 2, where we will address the much larger problem of improving the initial recall.
Why We Kept It Minimal
It’s important to understand the advanced retrieval techniques we deliberately avoided at this stage, such as BM25/TF-IDF scoring, fuzzy matching, abbreviation dictionaries, or biomedical synonym embeddings (e.g., SapBERT).
The goal was to isolate the core
Buffaly effect
: constrain then reason. This level proves that while constraints alone solve for safety, you cannot expect an LLM to fix a fundamentally flawed candidate list. This powerfully sets the stage for Level 2, where we address the core problem: improving candidate recall.
Buffaly Level 2: The Creative Query Expander — Solving the Recall Problem
Level 1 proved that an LLM can’t fix a poor candidate list; you can’t reason your way out of a “garbage in, garbage out” problem. The next logical step, therefore, was to use the LLM to create a better list .
Level 2 addresses the critical recall limitations of simple search by leveraging the LLM’s greatest strength: its linguistic creativity. Instead of just selecting from candidates, the LLM first acts as a query expander, brainstorming alternative clinical phrases, synonyms, and abbreviations to enrich the search. For example, given the term:
“heart failure with preserved EF,”
The LLM might generate variants that a clinician would use, but a simple search would miss:
“HFpEF,” “diastolic heart failure,” or “chronic heart failure with preserved ejection fraction.”
Each of these LLM-generated variants was then used to perform a new, exact search against the ontology, dramatically increasing the chances of finding the correct concept.
What We Ran
The process remained simple and safe, but added a crucial creative step:
- Run an exact ontology search on the original term.
- If no hit, ask the LLM to generate up to five alternate strings (synonyms, abbreviations, paraphrases).
- Run new exact searches on each of those strings.
- Finally, ask an LLM to choose the best concept from the combined list of candidates.
Critically, the LLM never outputs IDs, only search strings. Every potential answer remains fully grounded in the ontology.
Results
The impact on performance was immediate and substantial.
- Exact Match: 735 correct, 415 incorrect → 63.91% accuracy
- Looser Score: 904 correct, 246 incorrect → 78.61% accuracy
- Hallucinations: None.
Analysis
This level represents the first major breakthrough in performance. The gains over both the baseline and Level 1 are significant:
- vs. Baseline 1 (Naïve Non-AI): We saw a +10.00 point lift in exact accuracy, finding 115 more correct concepts . The looser score skyrocketed by +27.39 points .
- vs. Buffaly Level 1: Because Level 2 fixed the underlying recall problem, it also jumped +10.00 points in exact accuracy over Level 1, along with a +22.70 point gain in the looser score.
This result highlights a core Buffaly insight: while LLMs fail to reliably memorize concept IDs, they excel at generating the strings clinicians actually use. When given a few chances, the model successfully produced realistic surface forms like “HFpEF,” which then mapped cleanly via exact lookup.
The remaining gap between the looser and exact scores (
904 − 735 = 169 cases
) is the final piece of the puzzle. It tells us that in ~15% of cases, the LLM-expanded search found the
right neighborhood
but not the precise concept. This sets the stage perfectly for our final level, where an autonomous agent is designed to navigate that neighborhood and pinpoint the exact match.
Buffaly Level 3: The Autonomous Agent — From ‘Nearby’ to ‘Exact’
Level 2 was a breakthrough. By using an LLM to expand our search queries, we solved the fundamental recall problem, jumping from ~54% to ~79% on the looser accuracy score. However, it left us with 169 cases — nearly 15% of our dataset — that were in the right neighborhood but not the precise location.
To solve this “last mile” problem of precision, we unleashed Buffaly’s most advanced implementation: a fully autonomous agent.
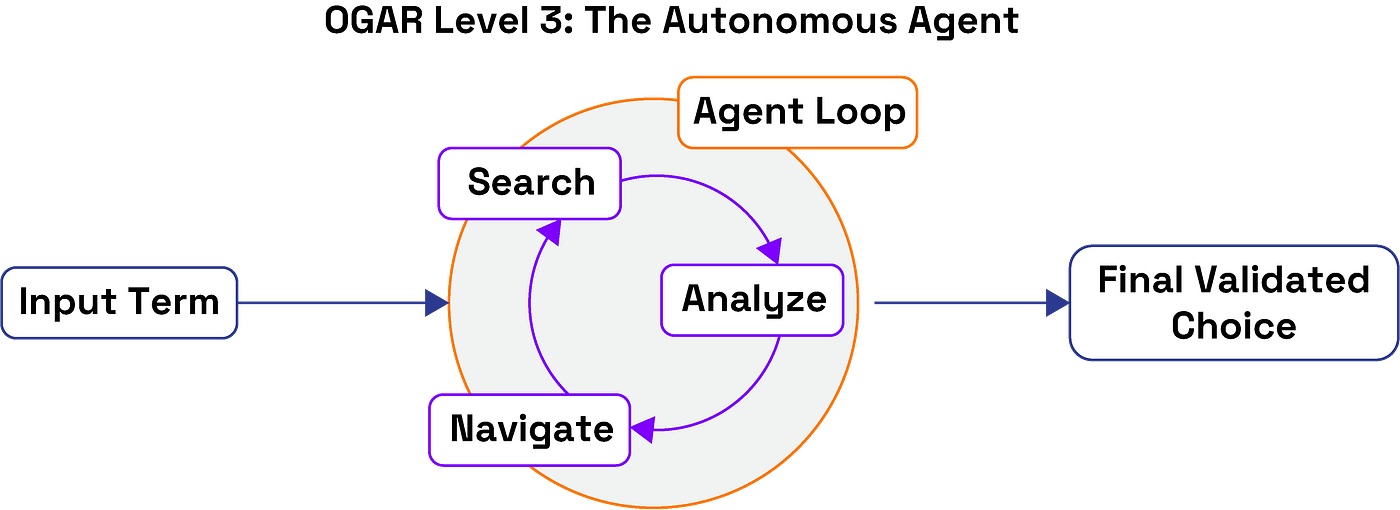
How the Agent Works
In this final level, the LLM is no longer a simple chooser or query expander; it becomes the pilot. Using our Buffaly framework, the LLM is equipped with a suite of ontology tools and a single goal: “Map the clinical term to the correct SNOMED concept.” It then enters an iterative reason-act loop:
- Search: It begins by performing searches to retrieve an initial set of candidates.
- Evaluate: It analyzes the results. Are they good enough? Is there ambiguity?
- Navigate & Refine: If uncertain, it uses its hierarchical navigation tool to explore the ontology, examining parent, child, or sibling concepts to better understand the context and subtle differences between candidates.
- Validate & Decide: Once satisfied, it validates its choice against the ontology’s rules and either locks in a final answer or, crucially, chooses to safely abstain if confidence remains low.
To ensure this was both efficient and cost-effective, we used a small model (“x-ai small”) and several practical optimizations, like starting with quick exact-match checks and minimizing redundant calls.
Results
The agent’s ability to iteratively refine its understanding delivered the highest performance of the entire study.
- Exact Match: 914 correct / 236 incorrect → 79.48% accuracy
- Looser Score (≥1 overlapping concept): 1,029 correct / 121 incorrect → 89.48% accuracy
Analysis
This represents the peak of the Buffaly framework’s performance, delivering substantial gains over every other method.
- A Monumental Lift Over Baselines: Compared to the best-performing pure LLM baseline (GPT-5 at 8.43%), the agent achieved a 9.4x higher exact-match accuracy , delivering a massive +71.05 point absolute gain and eliminating 77.6% of the errors.
- Solving the Precision Problem: The agent’s primary job was to convert the “near misses” from Level 2 into exact hits. It succeeded. The gap between the looser and exact scores shrank from 169 cases (14.7% of the dataset) in Level 2 down to just 115 cases (10.0%). This is concrete proof that the agent’s hierarchical navigation effectively resolved ambiguity and honed in on the precise concept.
- The Power of the Framework, Not Just the Model: And here is the most remarkable part: the agent was powered by the “x-ai small,” which is the Grok-4-fast-nonreasoning model . This is the exact same model that scored a near-zero 0.26% in our unguided baseline. This proves, unequivocally, that the model itself is not the source of success. The Buffaly framework transformed one of the worst-performing models from a useless guesser into an ~80% accurate reasoning engine.
The agent’s iterative retrieve-constrain-validate loop delivered high accuracy, zero hallucinations, and production-friendly cost-efficiency. It achieved results that raw LLMs and brute-force prompts simply cannot reach.
Summary of Results: A Head-to-Head Comparison
This table summarizes the performance of all tested methods on the 1,150-term Health Tags dataset. The progression clearly shows how grounding and increased autonomy dramatically improve performance while eliminating critical failures like hallucinations.
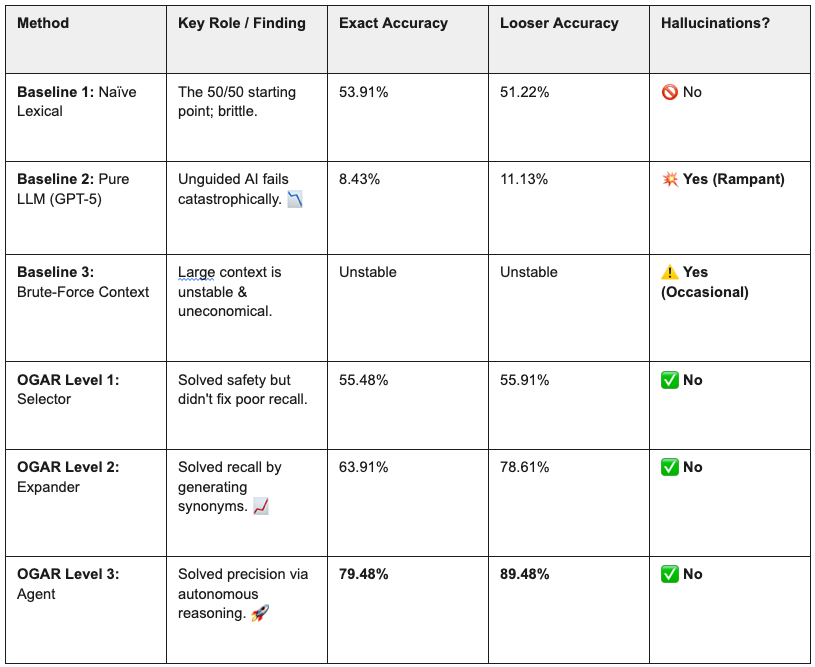
This three-level journey illustrates a clear and powerful principle. By leveraging ontology-guided constraints, we harness an LLM’s strengths while mitigating its weaknesses, dramatically increasing reliability and accuracy with each step.
- Level 1 (Selection): Solved the safety problem by eliminating hallucinations.
- Level 2 (Expansion): Solved the recall problem by using the LLM’s linguistic creativity to find more relevant candidates.
-
Level 3 (Agentic):
Solved the
precision
problem by using an autonomous agent to navigate and refine its choices, converting near misses into exact hits.
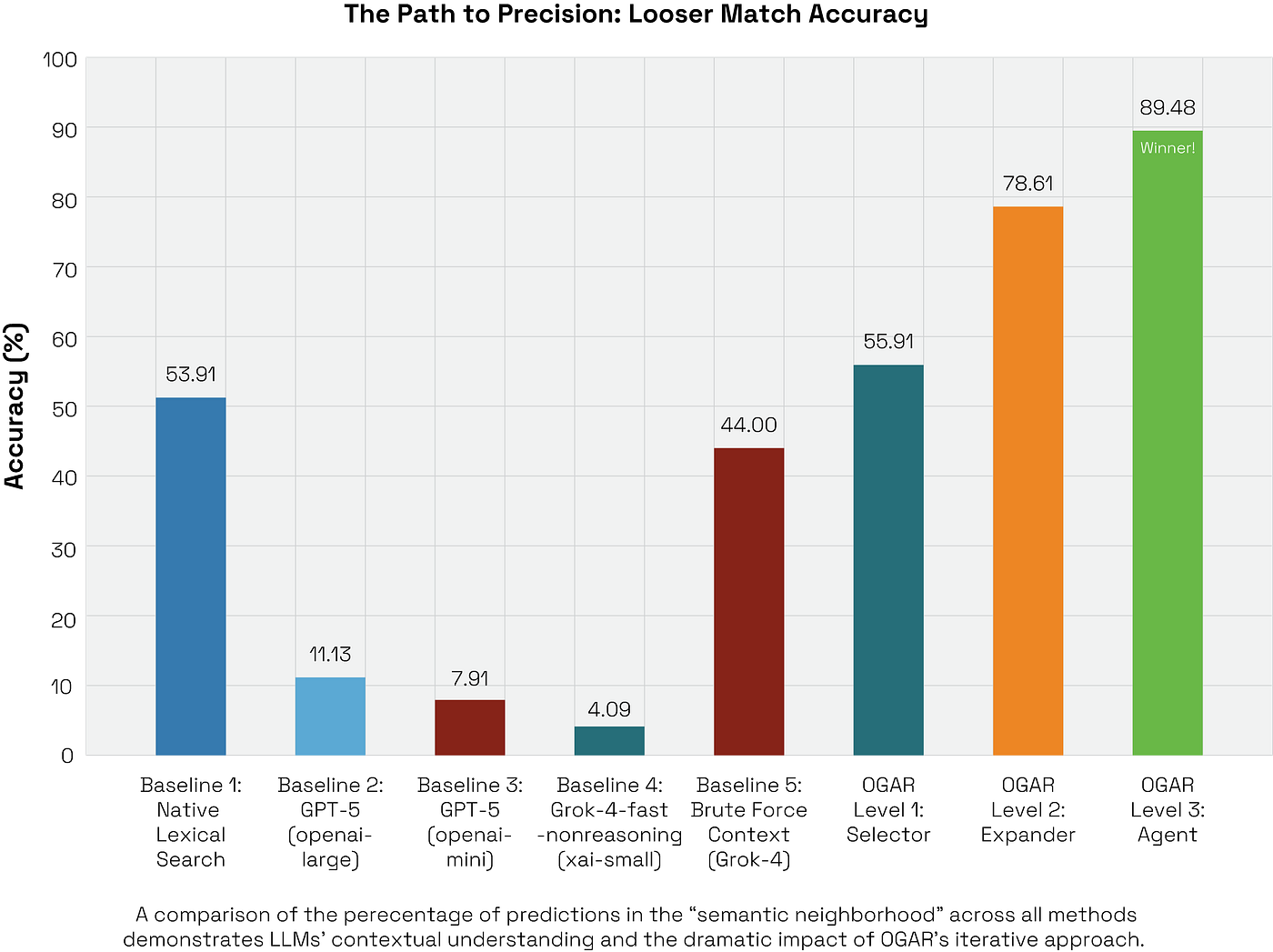
Analysis: Why Grounding, Not Scale, Is the Key to Reliability
The results are not just a scoreboard; they tell a fundamental story about how to build effective AI for high-stakes environments. The data points to one undeniable conclusion: the single biggest driver of accuracy and reliability wasn’t the size of the model, but the quality of its constraints. By grounding an LLM within the verifiable boundaries of an ontology, we transformed a brilliant-but-unreliable guesser into a high-performance reasoning engine.
Let’s break down exactly what this means.
The Architectural Flaw of Unguided AI
Our baseline tests revealed a hard truth: for precision tasks, unguided LLMs are built to fail. The catastrophic <9% accuracy wasn’t a fluke; it’s a feature of the architecture. LLMs are generative models optimized for probabilistic creativity, not deterministic fact-checking. Asking one to recall a specific SNOMED ID is a misuse of its core function.
- They can’t reliably memorize identifiers. A code like 44054006 is a sparse, arbitrary token, not semantic language. This makes it incredibly difficult to recall with certainty.
- They invent “imaginary codes.” An unguided LLM has no concept of “ground truth.” It doesn’t know if a code is valid, outdated, or a complete fabrication, so it generates plausible-sounding nonsense.
- The Grok-4 Paradox is the smoking gun. Its dismal 1.22% exact accuracy versus a strong 44.00% looser accuracy proves the point: the model understands clinical context but is structurally incapable of pinpointing a precise, canonical identifier .
Stuffing the prompt with more context, as the
$18,000 experiment
showed, doesn’t fix this. It only drowns the model in irrelevant information, leading to attention saturation and making the precision problem even harder.
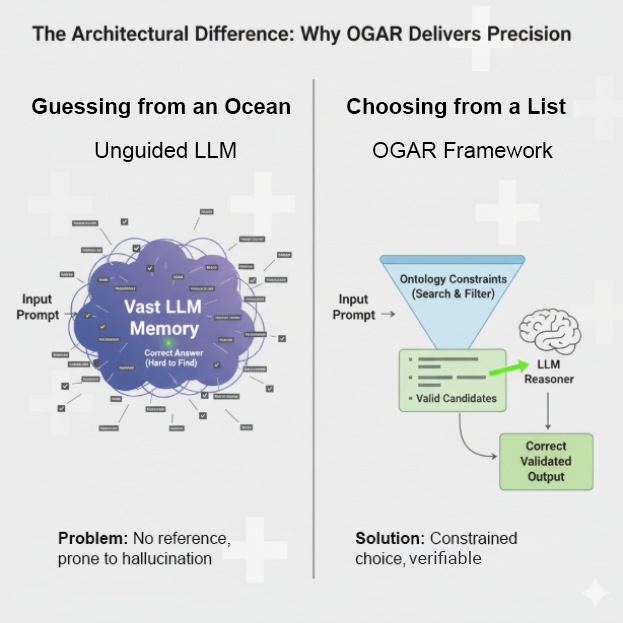
Buffaly’s Impact: A Fundamentally Smarter Approach
Buffaly didn’t just outperform the baselines — it demonstrated fundamentally smarter behavior by systematically addressing each of these failure points. Instead of asking the LLM to do what it’s bad at (recall IDs), it leverages what it’s good at (understanding language and making choices). The impact was dramatic:
- Hallucinations Disappeared. The first and most critical result was safety. By forcing the LLM into the role of a “Selector” from a multiple-choice list (Level 1), we immediately constrained its output to valid, ontology-approved concepts. This single design choice eliminated the risk of fabricated codes.
- Accuracy Soared. We achieved our ~80% accuracy through a powerful one-two punch. First, Level 2 acted as a “Creative Query Expander,” using the LLM’s linguistic talent to translate messy clinical shorthand (“HFpEF”) into formal terms the ontology could find. This solved the recall problem. Then, the Level 3 agent navigated the rich set of candidates, using the ontology’s hierarchy to resolve ambiguity and pinpoint the exact concept. This solved the precision problem.
- Cost and Complexity Plummeted. Our best results came from a small, economical model . This is a critical finding. High performance wasn’t achieved by scaling to a bigger, more expensive LLM, but by providing smarter boundaries. Buffaly proves that intelligent system design is a far more efficient path to accuracy than raw computational power.
- It Knew Its Own Limits. Perhaps most impressively, the Buffaly agent demonstrated the ability to intelligently abstain . Unlike a generative model that will always provide a best guess, the agent could determine when confidence was too low and stop — a crucial feature for building trustworthy AI in regulated fields like healthcare.
In the end, the path to reliable AI in specialized domains isn’t about building a bigger brain. It’s about giving that brain a map and a compass. Buffaly’s success proves that for clinical term mapping — and likely many other grounded reasoning tasks — clearly defined boundaries produce far better results than sheer scale or computational strength alone.
Conclusion: A Reusable Pattern for Trustworthy AI
Our journey through 1,150 clinical terms delivered a clear verdict: for tasks that demand precision, the path to reliable AI is not paved with bigger models or vaster context windows, but with smarter boundaries. By transforming a powerful LLM from an unguided guesser into a grounded decider, the Buffaly framework moved us from a catastrophic <9% accuracy to a robust ~80% , all while eliminating hallucinations and using a small, cost-effective model.
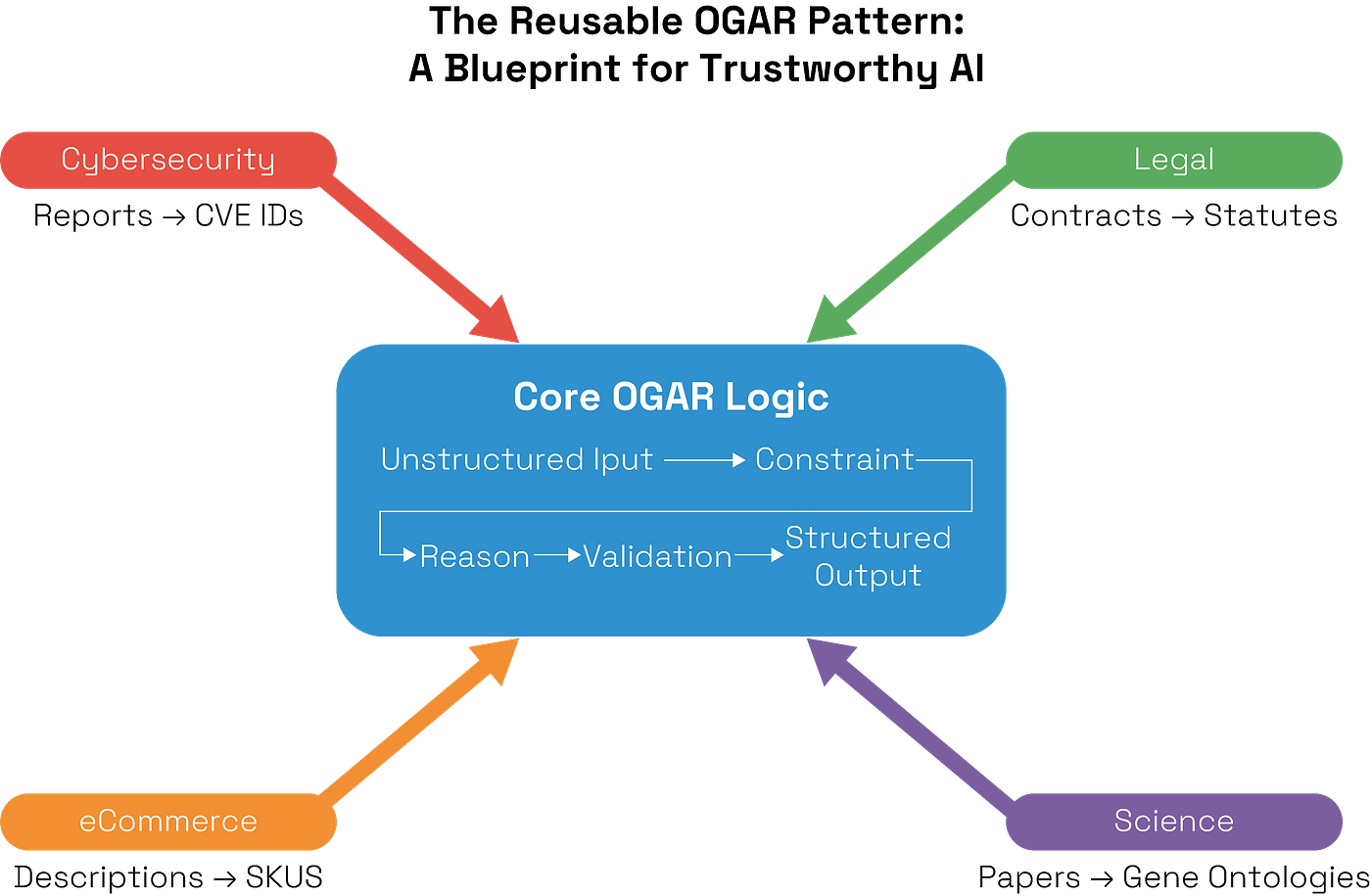
This is more than just a solution for SNOMED mapping; it’s a blueprint for a class of problems known as grounded symbolic mapping . These challenges share a common DNA:
- A structured ontology or controlled vocabulary provides a definitive set of correct answers.
- The input is unstructured, ambiguous human language (shorthand, slang, errors).
- Accuracy is critical , and mistakes have significant downstream consequences.
Buffaly provides a general, reusable design pattern for any of them. The core logic remains the same whether you are mapping:
- Cybersecurity reports to official CVE vulnerability IDs.
- Legal contract language to specific statutory references.
- Scientific papers to standardized chemical identifiers (ChEBI) or gene ontologies.
- E-commerce product descriptions to internal SKU taxonomies.
The Road Ahead: Building a More Reliable Ecosystem
This work is a significant step, but it also illuminates a clear path forward for building AI that is auditable, practical, and reliable. Our future efforts will focus on:
- Portability and Rapid Adaptation: Demonstrating Buffaly’s ability to be quickly adapted to other critical ontologies like ICD-10 (for billing), RxNorm (for medications), and CVE (for security), with a goal of creating automated ontology-to-adapter pipelines.
- Real-Time and Interactive Tools: Deploying agentic Buffaly in real-time applications, such as a clinical documentation assistant that suggests validated codes as a doctor types or a security tool that instantly maps threat intelligence to known vulnerabilities.
- Dynamic Ontology Management: Building robust mechanisms to handle evolving standards. This is crucial for maintaining accuracy as ontologies change versions, retire old concepts, and introduce new ones.
- Active Learning and Human-in-the-Loop Systems: Leveraging the agent’s ability to intelligently abstain . By routing uncertain mappings directly to human experts, we can create a powerful feedback loop where human validation continually improves the system’s performance.
Ultimately, Buffaly represents a shift in philosophy — a move away from the endless pursuit of scale and toward a future built on precision and auditable reasoning. By giving our powerful models a map and a compass, we can finally begin to deploy them with the confidence and reliability that critical real-world applications demand.
Special thanks to Dr. Tisloh Danboyi for his invaluable collaboration and for providing the foundational dataset that made this research possible