


This blog outlines a groundbreaking proof of concept for reimagining medical ontologies and artificial intelligence. Buffaly demonstrates how large language models (LLMs) can unexpectedly enable symbolic methods to reach unprecedented levels of effectiveness. This fusion delivers the best of both worlds: completely transparent, "white box" systems capable of autonomous learning directly from raw data. Unlike traditional neural network-based approaches, Buffaly can incrementally learn from very few examples, marking a significant advancement beyond conventional methodologies.
Related FairPath Resources
We believe this neurosymbolic paradigm represents the next major evolutionary step in AI following large language models.
Why Neurosymbolic? Bridging Symbolic Precision with Neural Flexibility
Buffaly’s core strength lies in its neurosymbolic architecture —combining the interpretability and precision of symbolic logic with the flexibility and adaptability of neural networks. Traditional AI systems, predominantly neural-based, suffer from a lack of transparency and explainability, critical factors in healthcare applications. By integrating explicit symbolic representations with neural language models, Buffaly enables dynamic, transparent, and comprehensible knowledge acquisition and reasoning.
With this approach, Buffaly efficiently learns hundreds of new terms, dynamically adding thousands of lines of self-generated code during each training session without interruptions.
Key Breakthroughs: A First-of-its-Kind Platform
Buffaly introduces three critical innovations that distinguish it within the clinical informatics landscape:
Unified Ontology Ecosystem:
Buffaly integrates multiple specialized ontologies—including the complete ICD-10-CM ontology (over 15,000 codes), selected portions of SNOMED CT (currently ~20,000 dynamically loaded concepts), and foundational linguistic resources such as WordNet and VerbNet (comprising an additional 15,000 words)—into one cohesive, highly interoperable framework. This unified approach ensures immediate semantic interoperability across diverse clinical and linguistic terminologies.
Rapid and Efficient Ontology Representation:
Utilizing ProtoScript as its foundational ontology representation language, Buffaly streamlines ontology management significantly compared to traditional SQL, XML-based, or RDF based systems. ProtoScript provides intuitive, hierarchical definitions that greatly simplify ontology integration, maintenance, and real-time updates.
Example: Complex ICD-10 hierarchical structures and detailed SNOMED CT relationships, which are typically cumbersome in XML or RDF formats, are concisely represented in easily readable ProtoScript code. This clarity greatly enhances efficiency and accessibility for both technical developers and clinical experts.
Dynamic Large Language Model Integration:
Buffaly’s seamless integration with large language models (LLMs) represents a revolutionary leap forward. It dynamically identifies, learns, and incorporates new clinical terminology transparently and auditably. This automatic self-extension capability enables Buffaly to continuously evolve and scale its knowledge base while providing full explainability and clear traceability for every mapping and decision.
Collectively, these innovations empower Buffaly to deliver unparalleled clarity, speed, and adaptability within clinical informatics, ensuring precise patient-to-resource alignment and significantly advancing digital healthcare capabilities.
Buffaly System Architecture: The Big Picture
Layered Ontology Design: An Overview
The Buffaly system employs a robust, multi-layered ontology framework that integrates diverse semantic resources into a coherent, unified knowledge base. Each layer addresses specific semantic dimensions critical for comprehensive clinical understanding and precise medical coding:
-
Lexical Ontology Layer:
This foundational layer incorporates lexical databases such as WordNet, VerbNet, FrameNet, and PropBank. It provides the semantic grounding for natural language processing tasks, enriching Buffaly with a vast vocabulary (15,000+ preloaded terms) and nuanced semantic relationships essential for accurately interpreting clinical narratives.
Example: WordNet captures synonyms and antonyms (e.g., "enlarged" and "dilated"), enabling the system to recognize semantic equivalences in clinical documentation.
[Lexeme.SingularPlural(
"dilatation"
,
"dilatations"
)]
[Synset(
"dilatation.n.01"
)]
[Definition(
"the condition of being stretched or expanded, especially a body cavity, part, or opening"
)]
partial prototype DilatationObject : Condition
{
}
-
Medical Coding Ontology Layer (ICD-10-CM):
This layer hosts a comprehensive representation of the ICD-10-CM ontology, encompassing over 15,000 medical diagnosis codes. It structures medical information hierarchically (chapters, blocks, categories, and codes) to streamline accurate coding and reporting.
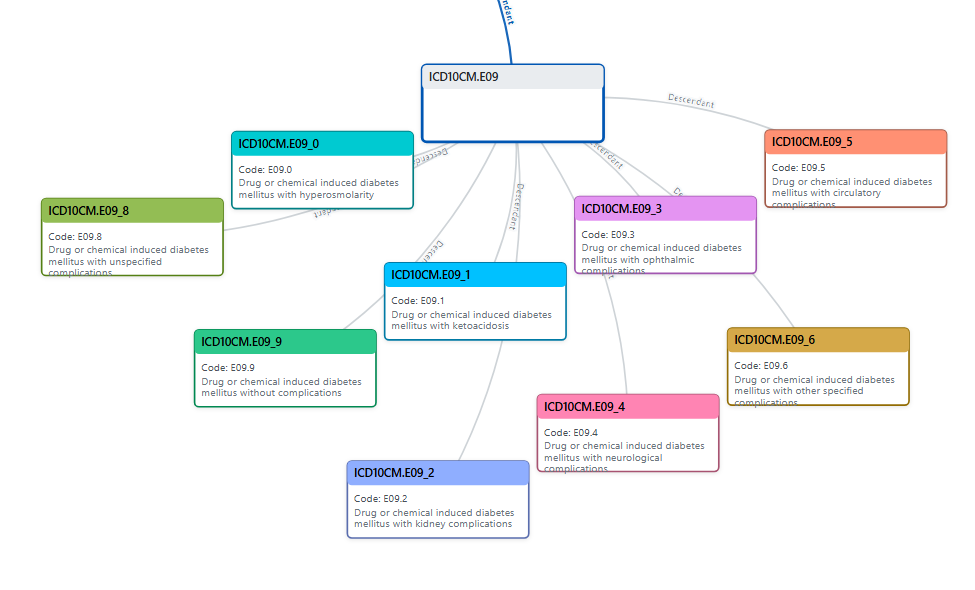
A textual based representation of of branch:
ICD10CM.E09
├── [
0
] = ICD10CM.E09_0
│ ├── [
0
] = ICD10CM.E09_00
│ └── [
1
] = ICD10CM.E09_01
├── [
1
] = ICD10CM.E09_1
│ ├── [
0
] = ICD10CM.E09_10
│ └── [
1
] = ICD10CM.E09_11
├── [
2
] = ICD10CM.E09_2
│ ├── [
0
] = ICD10CM.E09_22
│ ├── [
1
] = ICD10CM.E09_29
│ └── [
2
] = ICD10CM.E09_21
├── [
3
] = ICD10CM.E09_3
│ ├── [
0
] = ICD10CM.E09_34
│ │ ├── [
0
] = ICD10CM.E09_349
│ │ └── [
1
] = ICD10CM.E09_341
│ ├── [
1
] = ICD10CM.E09_36
│ ├── [
2
] = ICD10CM.E09_32
│ │ ├── [
0
] = ICD10CM.E09_321
│ │ └── [
1
] = ICD10CM.E09_329
│ ├── [
3
] = ICD10CM.E09_39
│ ├── [
4
] = ICD10CM.E09_35
│ │ ├── [
0
] = ICD10CM.E09_352
│ │ ├── [
1
] = ICD10CM.E09_351
│ │ ├── [
2
] = ICD10CM.E09_359
│ │ ├── [
3
] = ICD10CM.E09_354
│ │ ├── [
4
] = ICD10CM.E09_353
│ │ └── [
5
] = ICD10CM.E09_355
│ ├── [
5
] = ICD10CM.E09_37
│ ├── [
6
] = ICD10CM.E09_31
│ │ ├── [
0
] = ICD10CM.E09_311
│ │ └── [
1
] = ICD10CM.E09_319
│ └── [
7
] = ICD10CM.E09_33
│ ├── [
0
] = ICD10CM.E09_331
│ └── [
1
] = ICD10CM.E09_339
├── [
4
] = ICD10CM.E09_4
│ ├── [
0
] = ICD10CM.E09_44
│ ├── [
1
] = ICD10CM.E09_40
│ ├── [
2
] = ICD10CM.E09_42
│ ├── [
3
] = ICD10CM.E09_49
│ ├── [
4
] = ICD10CM.E09_41
│ └── [
5
] = ICD10CM.E09_43
├── [
5
] = ICD10CM.E09_5
│ ├── [
0
] = ICD10CM.E09_52
│ ├── [
1
] = ICD10CM.E09_59
│ └── [
2
] = ICD10CM.E09_51
├── [
6
] = ICD10CM.E09_6
│ ├── [
0
] = ICD10CM.E09_64
│ │ ├── [
0
] = ICD10CM.E09_649
│ │ └── [
1
] = ICD10CM.E09_641
│ ├── [
1
] = ICD10CM.E09_62
│ │ ├── [
0
] = ICD10CM.E09_622
│ │ ├── [
1
] = ICD10CM.E09_621
│ │ ├── [
2
] = ICD10CM.E09_620
│ │ └── [
3
] = ICD10CM.E09_628
│ ├── [
2
] = ICD10CM.E09_69
│ ├── [
3
] = ICD10CM.E09_65
│ ├── [
4
] = ICD10CM.E09_61
│ │ ├── [
0
] = ICD10CM.E09_610
│ │ └── [
1
] = ICD10CM.E09_618
│ └── [
5
] = ICD10CM.E09_63
│ ├── [
0
] = ICD10CM.E09_630
│ └── [
1
] = ICD10CM.E09_638
├── [
7
] = ICD10CM.E09_8
└── [
8
] = ICD10CM.E09_9
-
Clinical Terminology Ontology Layer (SNOMED CT):
This layer includes a selective loading mechanism (lazy loading) to efficiently manage the extensive granularity of SNOMED CT, selectively integrating relevant clinical terms (approximately 10,000-20,000 currently loaded out of a potential 300,000).
An example Prototype loaded from the SNOMED-CT Ontology
partial prototype SnoMed.Sct_Cardiomegaly_8186001 : SnoMed.ClinicalConcept,
SnoMed.Sct_StructuralDisorderOfHeart_128599005
{
MappedIcdCodes = [
"I51.7"
];
Synonyms = [
"Cardiomegaly"
,
"Enlarged heart"
];
PreferredTerm =
"Cardiomegaly"
;
FullySpecifiedName =
"Cardiomegaly (disorder)"
;
ConceptId =
"8186001"
;
}
The Clinical Ontology: Bridging Natural Language and Medical Coding
Purpose: Semantic Translation Between Ontology Layers
The Clinical Ontology acts as an intermediate semantic framework, enabling Buffaly to align natural language terms with standardized medical codes effectively. Its primary role is to structure clinical concepts specifically tailored to each application's requirements. For instance, when assigning ICD-10 codes to clinical notes, the ontology focuses its "understanding" around precise medical coding. Conversely, when categorizing medical conditions into broader, patient-friendly groupings, the ontology adapts its structure accordingly.
Additionally, the Clinical Ontology provides an essential abstraction layer, separating lexical variations from underlying meanings (sememes). This allows Buffaly to maintain consistent clinical reasoning independently of specific languages or terminologies. For example:
-
"Heart" (English) → HeartSememe
-
"Corazón" (Spanish) → HeartSememe
-
"Coração" (Portuguese) → HeartSememe
Here, distinct lexical units across different languages are mapped onto the same fundamental semantic concept (sememe). By operating at this semantic level, the Clinical Ontology ensures robustness, flexibility, and language-independence, enabling accurate clinical interpretation across diverse linguistic contexts.
Example:
ICD-10 code I51.7 broadly covers "Cardiomegaly," while SNOMED CT includes highly specific terms like "Dilated cardiomyopathy" and "Left ventricular hypertrophy." The clinical ontology layer reconciles these by dynamically forming intermediate hierarchies.
//Root object mapping to ICD-10-CM I51.7
partial prototype ClinicalOntology.Cardiomegaly : ClinicalOntology.Condition
{
CodeValue =
"I51.7"
;
}
//SNOMED-CT derived sub-objects (a subset)
partial prototype ClinicalOntology.Cardiac_Dilatation : ClinicalOntology.Condition, ClinicalOntology.Cardiomegaly
{
Concepts = [
"SnoMed.Sct_CardiacDilatation_71932004"
];
CodeValue =
"I51.7"
;
}
partial prototype ClinicalOntology.Cardiac_Ventricular_Dilatation : ClinicalOntology.Condition, ClinicalOntology.Cardiomegaly
{
Concepts = [
"SnoMed.Sct_CardiacVentricularDilatation_6210001"
];
CodeValue =
"I51.7"
;
}
partial prototype ClinicalOntology.Right_Cardiac_Ventricular_Dilatation : ClinicalOntology.Condition
{
Concepts = [
"SnoMed.Sct_RightCardiacVentricularDilatation_253522006"
];
CodeValue =
"I51.7"
;
}
Further Understanding
There is no 1 to 1 mapping between ICD-10-CM and SNOMED-CT, nor between English and these Ontologies
- Cardiomegaly has 1 ICD-10-CM Prototype and 47 SNOMED-CT Prototypes
-
From English to ICD-10-CM there are two terms
- Cardiomegaly, Enlarged heart
-
From English via SNOMED-CT to ICD-10-CM there are close to 100 terms:
- Dilatation of cardiac ventricle
- Cardiac ventricular dilatation
- Right cardiac ventricular dilatation
- Dilatation of right cardiac ventricle
- Acquired dilatation of right cardiac ventricle
- Dilatation of left cardiac ventricle
- Left cardiac ventricular dilatation
- Acquired dilatation of left cardiac ventricle
- Acquired left ventricular dilation
- Cardiomegaly
- Enlarged heart
- Cardiac dilatation
- …
The Clinical Ontology provides a flexible ontology that ties all of these together. For example:
- “Dialation of right cardiac ventricle” is a SNOMED-CT concept
- It is located under the ClinicalOntology.Cardiomegaly node
- It maps to I51.7 in the ICD-10 hierarchy
We can easily extend this layer with more information that does not exist within ICD-10-CM or SNOMED-CT:
partial prototype ClinicalOntology.Right_Cardiac_Ventricular_Dilatation : ClinicalOntology.Condition, ClinicalOntology.Cardiomegaly
{
Concepts = [
"SnoMed.Sct_RightCardiacVentricularDilatation_253522006"
];
CodeValue =
"I51.7"
;
FriendlyCategory =
"Cardiovascular Disorders"
;
}
Buffaly NLU: Continuous Learning of Clinical Terminology
-
Dynamic Word Acquisition via LLM:
Buffaly NLU continuously learns and adapts to new clinical terms encountered in electronic health records (EHRs) using integrated Large Language Models (LLMs). This neurosymbolic approach ensures rapid, automated updates without human intervention.
Example: Encountering a new abbreviation like "LVEF" (Left Ventricular Ejection Fraction) triggers the LLM to define the term, which Buffaly then automatically incorporates into its clinical ontology.
-
Automated Prototype Generation and Integration:
New terms identified by the LLM are dynamically converted into structured prototypes using ProtoScript, facilitating immediate integration and ensuring that Buffaly’s knowledge base remains current and comprehensive.
ProtoScript: The Common Language for Ontology Representation
ProtoScript is a flexible, prototype-based ontology language that enables intuitive and dynamic representation of complex, interconnected knowledge structures. Prototypes function as both templates and instances, allowing seamless inheritance from multiple parents and easy adaptation at runtime. This unique design simplifies integration across diverse ontologies, facilitating transparent reasoning and rapid updates.
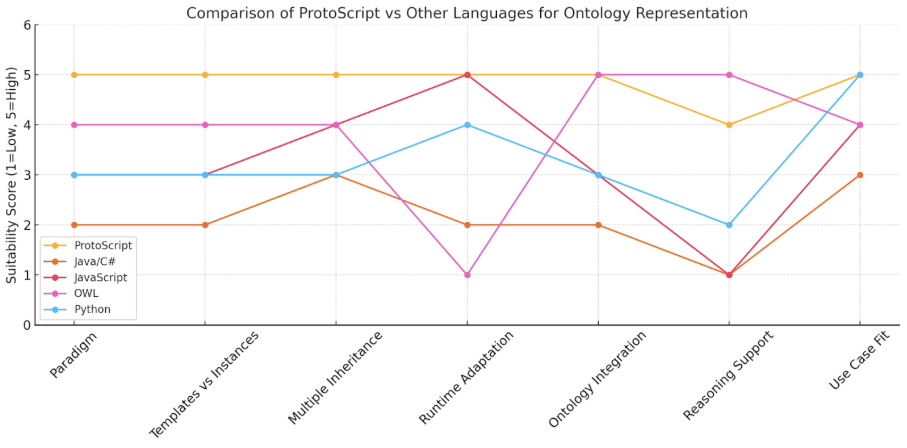
Advantages Over Traditional Methods (SQL/XML):
ProtoScript isn’t trying to replace RDF for global semantic standards—it’s a pragmatic alternative for systems that need agility, adaptability, and developer-friendliness in local or semi-structured knowledge graphs. Think of it as the JavaScript of ontology, where RDF is more like XML + formal logic.
Example: The following shows a possible ProtoScript representation of the Cardiomegaly Clinical Object.
// ProtoScript representation of Cardiomegaly (ICD-10: I51.7)
prototype Cardiomegaly : ClinicalCondition {
ICD10Code =
"I51.7"
;
Description =
"Cardiomegaly"
;
Synonyms = [
"Enlarged Heart"
,
"Cardiac Enlargement"
];
SNOMEDMapping = [
8186001
];
// SNOMED CT Concept ID
}
Ontologies are traditionally represented in RDF:
<!-- RDF/XML representation
of
Cardiomegaly (SNOMED CT ID:
8186001
) -->
<
rdf:RDF
xmlns:rdf
=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:snomed
=
"http://snomed.info/id/"
xmlns:rdfs
=
"http://www.w3.org/2000/01/rdf-schema#"
>
<!-- Cardiomegaly Concept -->
<
rdf:Description
rdf:about
=
"http://snomed.info/id/8186001"
>
<
rdfs:label
>
Cardiomegaly (disorder)
</
rdfs:label
>
<
snomed:conceptId
>
8186001
</
snomed:conceptId
>
<
snomed:fullySpecifiedName
>
Cardiomegaly (disorder)
</
snomed:fullySpecifiedName
>
<
snomed:synonym
>
Enlarged heart
</
snomed:synonym
>
<
snomed:synonym
>
Cardiac enlargement
</
snomed:synonym
>
<
snomed:definitionStatus
rdf:resource
=
"http://snomed.info/id/900000000000073002"
/>
<!-- Fully defined -->
<
snomed:isA
rdf:resource
=
"http://snomed.info/id/56265001"
/>
<!-- Heart disease -->
<
snomed:isA
rdf:resource
=
"http://snomed.info/id/368009"
/>
<!-- Disorder of cardiac structure -->
<
snomed:mappedToICD10
rdf:resource
=
"http://hl7.org/fhir/sid/icd-10-cm/I51.7"
/>
<
snomed:active
>
true
</
snomed:active
>
</
rdf:Description
>
<!-- Parent concept: Heart disease -->
<
rdf:Description
rdf:about
=
"http://snomed.info/id/56265001"
>
<
rdfs:label
>
Heart disease (disorder)
</
rdfs:label
>
<
snomed:conceptId
>
56265001
</
snomed:conceptId
>
</
rdf:Description
>
<!-- Parent concept: Disorder of cardiac structure -->
<
rdf:Description
rdf:about
=
"http://snomed.info/id/368009"
>
<
rdfs:label
>
Disorder of cardiac structure (disorder)
</
rdfs:label
>
<
snomed:conceptId
>
368009
</
snomed:conceptId
>
</
rdf:Description
>
<!-- ICD-10-CM mapping -->
<
rdf:Description
rdf:about
=
"http://hl7.org/fhir/sid/icd-10-cm/I51.7"
>
<
rdfs:label
>
Cardiomegaly
</
rdfs:label
>
<
snomed:code
>
I51.7
</
snomed:code
>
<
snomed:codeSystem
>
ICD-10-CM
</
snomed:codeSystem
>
</
rdf:Description
>
</
rdf:RDF
>
Efficiency Gains and Scalability:
ProtoScript dramatically accelerates development cycles and enhances scalability, especially vital when managing expansive ontologies or adapting to continuous semantic expansion driven by neurosymbolic learning. Its flexible prototype-based design facilitates immediate, real-time updates, easily accommodating new ICD-10 codes or SNOMED CT concepts as they emerge.
Training
Step-by-Step Training Example: ICD-10 Code I51.7 ("Cardiomegaly")
Step 0: Loading Lexical and Medical Ontologies
The Buffaly system begins by loading foundational ontologies into its semantic graph, including:
- Lexical Ontologies (WordNet, VerbNet, FrameNet, PropBank): Buffaly preloads over 15,000 general linguistic terms, establishing an extensive base for language understanding. For example, the term "enlarge" is semantically linked to "expand" and "increase," providing foundational meaning essential for interpreting terms like "cardiac enlargement."
-
Medical Coding Ontologies
:
- ICD-10-CM Ontology : Buffaly fully integrates around 15,000 ICD-10-CM codes, structured hierarchically into chapters, blocks, categories, and individual codes (e.g., "Cardiomegaly" as code I51.7).
- SNOMED CT Ontology : Due to its extensive size (approximately 300,000 concepts), SNOMED CT concepts are loaded dynamically and incrementally as needed. For example, encountering "dilated cardiomyopathy" triggers the dynamic loading of SNOMED CT concept ID 195029002.
Step 1: Initial Prototype from ICD-10 Ontology
We start by defining the ICD-10-CM prototype, representing the clinical concept "Cardiomegaly":
partial prototype ICD10CM.I51_7 : ICD10CM.I51
{
init
{
Includes = [
"Cardiac dilatation"
,
"Cardiac hypertrophy"
,
"Ventricular dilatation"
];
Description =
"Cardiomegaly"
;
CodeValue =
"I51.7"
;
}
}
The goal is to teach Buffaly the semantic association between the descriptive terms listed under
Includes
and the standardized code
I51.7.
Step 2: Training with a Single Example ("Cardiac dilatation")
Buffaly can rapidly learn from a single example. Let's process the phrase "Cardiac dilatation" .
Tokenization
We first tokenize the phrase at word boundaries, without using stemming:
-
"Cardiac"
-
"dilatation"
Why avoid stemming?
Stemming would reduce "dilatation," "dilation," and "dilate" to a single, ambiguous stem. Buffaly instead creates detailed semantic mappings that preserve nuance and relationships between related word forms.
Step 3: Lexical Analysis of Tokens
Token: "Cardiac"
Buffaly already knows "cardiac" through its lexical ontologies (WordNet):
// Cardiac Semantic Group
partial prototype CardiacSememe : Sememe;
partial prototype Cardiac : CardiacSememe;
partial prototype CardiacObject : CardiacSememe;
partial prototype CardiacnessObject : CardiacSememe;
partial prototype CardiumObject : CardiacSememe;
Token: "dilatation" (New Word)
The word "dilatation" isn't known by default, so Buffaly consults its integrated Large Language Model (LLM) for assistance:
LLM provides the following information (illustrative):
-
"Dilatation" means "the act of expanding or enlarging."
-
Related forms: "dilation," "dilate," "dilated," etc.
-
Clarifies that "dilatation" and "dilation" are synonyms.
Buffaly then automatically generates prototypes to represent these related word forms:
// Dilatation Semantic Group
partial prototype DilatationSememe : DilationDilatationSememe;
partial prototype DilatationObject : DilatationSememe;
partial prototype DilatationalQualifier : DilatationSememe;
partial prototype DilatedQualifier : DilatationSememe;
partial prototype DilatingQualifier : DilatationSememe;
partial prototype DilationObject : DilatationSememe;
partial prototype DilateBase : DilationDilatationSememe;
partial prototype DilatedlyAdverbQualifier : DilationDilatationSememe;
// Dilation Semantic Group
partial prototype DilationSememe : DilationDilatationSememe;
partial prototype DilatorObject : DilationSememe;
This creates a detailed mini-ontology around these semantically related words, capturing nuanced differences without losing information.
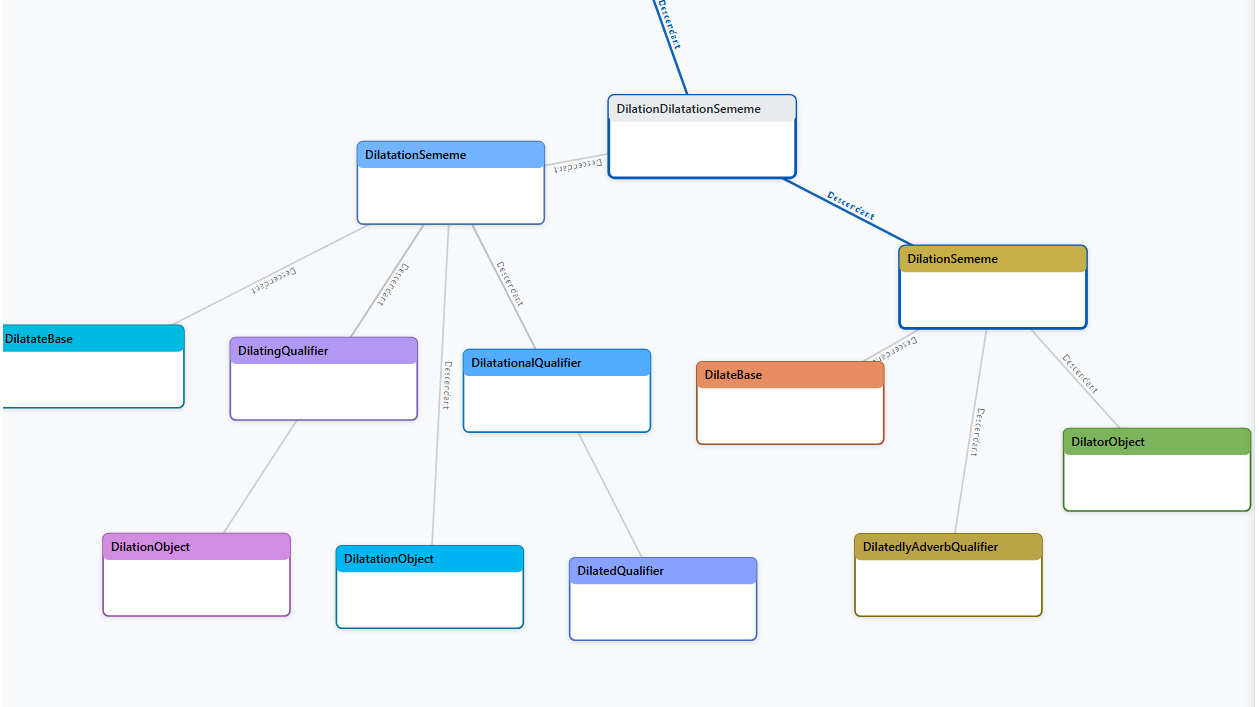
Step 4: Mapping to the Clinical Ontology
With the lexical meanings clear, Buffaly now connects these terms to the Clinical Ontology , creating a meaningful intermediate representation:
partial prototype ClinicalOntology.Cardiomegaly : ClinicalOntology.Condition
{
init
{
Concepts = [
"SnoMed.Sct_Cardiomegaly_8186001"
];
CodeValue =
"I51.7"
;
}
}
This prototype explicitly links to:
-
ICD-10 Code:
I51.7
-
SNOMED CT Concept:
Sct_Cardiomegaly_8186001
(The SNOMED CT concept, while typically integrated separately, is shown here explicitly for clarity.)
Step 5: Creation of Semantic Bridge ("Sememe" Representation)
To unify terminology across different lexical forms and ensure semantic consistency, Buffaly establishes a semantic bridge (an intermediate "Sememe"):
partial prototype ClinicalOntology.Cardiac_DilatationSememe : Sememe, BagOfFeatures, ClinicalOntology.Cardiomegaly
{
Children = [CardiacSememe, DilatationSememe];
}
This sememe links directly to the clinical concept prototype (
ClinicalOntology.Cardiomegaly
). Thus, phrases like "Cardiac dilatation," "heart dilation," or "enlarged heart" can map accurately to standardized clinical codes and concepts.
Result of Training Phase
From a single example ("Cardiac dilatation"), Buffaly has dynamically:
-
Learned a new word ("dilatation") and related terms via LLM integration.
-
Constructed a detailed semantic structure (sememes) capturing lexical nuances.
-
Linked these lexical forms explicitly to standardized clinical representations in both ICD-10 and SNOMED CT.
Created a reusable intermediate Clinical Ontology prototype ensuring future semantic consistency and transparency.
Why Statistical Methods Aren’t Necessary with Buffaly’s Neurosymbolic Approach
The Buffaly system employs a neurosymbolic architecture that integrates explicit symbolic representation with neural language models. At the core, Buffaly uses a structured semantic layer—specifically, a simple but highly effective "Bag of Features" mechanism—to map clinical phrases to standardized medical codes.
Unlike purely statistical methods (e.g., word embeddings) that represent words as opaque numeric vectors, Buffaly represents words and concepts explicitly through structured, symbolic prototypes (sememes). Each sememe captures precise semantic meaning, explicitly linking words, synonyms, abbreviations, and variants without loss of detail or interpretability.
Key reasons why statistical embeddings are unnecessary:
-
Explicit Semantic Structure:
Symbolic prototypes (sememes) represent meaning directly and explicitly. There's no need to infer meaning indirectly through statistical similarity. When Buffaly learns a new term, it links it clearly and transparently to known semantic entities.
-
Transparent and Explainable:
The neurosymbolic method ensures complete interpretability. Every decision—why a particular clinical phrase maps to a standardized code—is explicitly justified through structured semantic relationships. Statistical embeddings, on the other hand, are inherently opaque, making explanations difficult or impossible.
-
Near 100% Accuracy with Simple Mechanisms:
Even with straightforward techniques such as the Bag of Features method, Buffaly achieves near-perfect accuracy on standardized test sets. Complex statistical methods offer little additional advantage in accuracy and introduce complexity without the corresponding benefit in transparency.
-
Preservation of Linguistic Nuance:
Unlike embedding-based methods, which compress multiple meanings into dense numerical spaces (potentially losing linguistic nuance), Buffaly maintains multiple, distinct semantic representations for words and concepts. This preserves important medical distinctions, such as subtle variations in clinical terminology.
In essence
, Buffaly's explicit neurosymbolic framework already provides comprehensive semantic understanding, accuracy, and interpretability. The statistical generalizations inherent in methods like word embeddings become redundant, unnecessary, and less desirable compared to the transparency and precision offered by symbolic, sememe-based representation.
Prediction
When processing new clinical inputs, Buffaly follows a systematic, step-by-step prediction workflow, ensuring accurate semantic interpretation and mapping to the appropriate standardized clinical entities. This workflow mirrors the training process, leveraging Buffaly’s integrated neurosymbolic architecture:
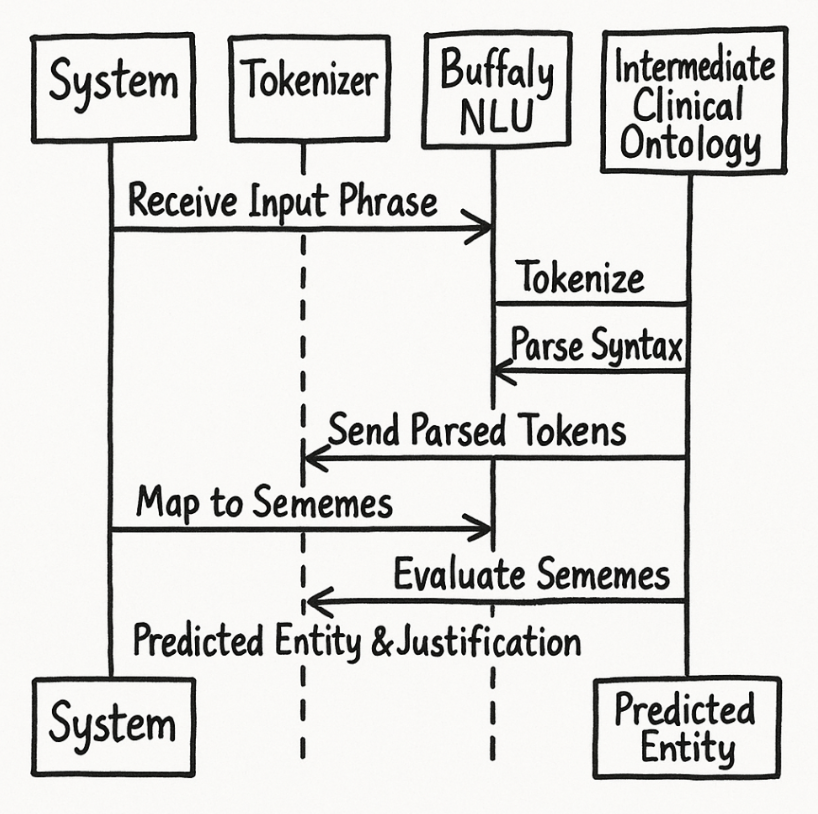
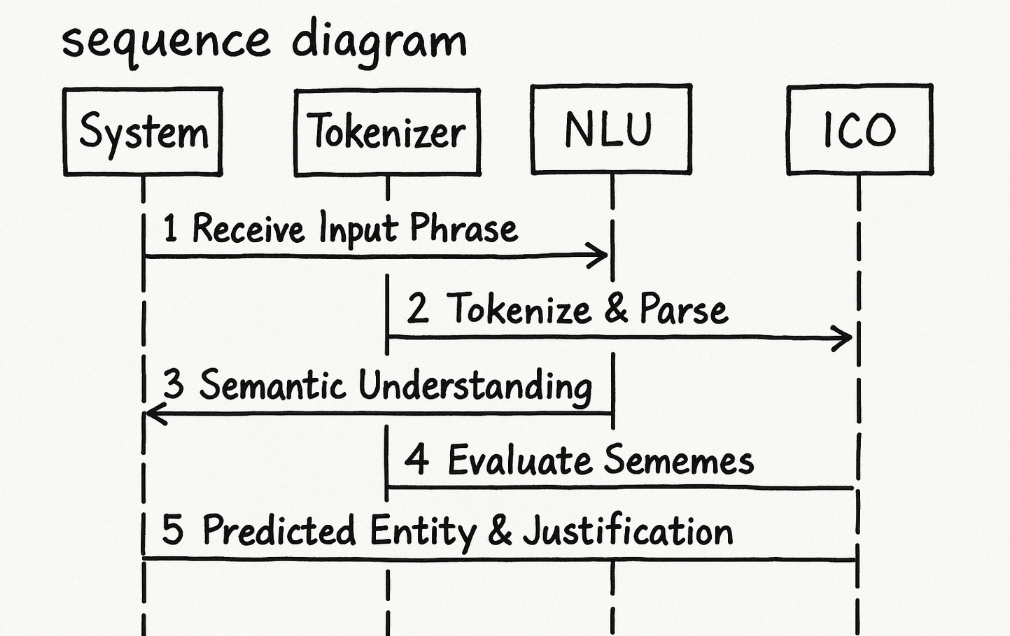
Step 1: Receive an Input Phrase
- Input: A raw clinical phrase or narrative from electronic health records (EHRs), clinical notes, or user queries.
- Example: "Patient shows signs of cardiac dilatation."
Step 2: Tokenization and Syntactic Parsing
-
Process:
-
The input phrase is segmented into discrete tokens strictly at word boundaries.
-
No stemming or lemmatization
is performed at this stage; full lexical forms are preserved to maintain semantic precision.
-
Next, Buffaly performs a
syntactic analysis
using linguistic data from integrated lexical ontologies (WordNet, VerbNet, PropBank, FrameNet).
-
This produces a structured syntactic representation, capturing grammatical relationships and dependencies.
-
The input phrase is segmented into discrete tokens strictly at word boundaries.
-
Example Tokens:
-
"Patient", "shows", "signs", "of", "cardiac", "dilatation"
-
- Syntactic Representation (Example):
Shows
├── Subject = Patient
├── Object = Signs
├── Preposition = Of
└── LinkedObject = Enlarged_HeartSememe
-
Important Note:
The exact syntactic accuracy of the parsing is not critical, provided it remains semi-consistent . Even if syntactic structures are incorrect, their consistent patterns still yield valuable predictive signals during feature extraction.
Step 3: Buffaly NLU Semantic Understanding
Process:
- Each token (and token sequence) is evaluated by the Buffaly NLU layer, referencing previously learned lexical and clinical ontologies.
- Semantic and syntactic structures are identified, disambiguating terms, recognizing synonyms, abbreviations, and semantic roots.
- Buffaly explicitly maps these tokens to symbolic representations (sememes).
Example:
-
"cardiac"→ linked explicitly toCardiacSememe -
"dilatation"→ linked explicitly toDilatationSememe(previously learned via LLM assistance)
Step 4: Intermediate Clinical Ontology Evaluation
Process:
- The system evaluates identified sememes against the intermediate clinical ontology layer, using semantic matching (typically via a simple and effective Bag of Features approach).
- Sememes from the input phrase are matched with intermediate semantic prototypes, bridging the gap between natural language and standardized coding ontologies (ICD-10, SNOMED CT).
Example Matching:
-
Tokens
"cardiac"and"dilatation"combine to activate theEnlarged_HeartSememe(which connects directly to clinical ontology concepts likeCardiomegaly).
Step 5: Predicted Clinical Entity
Process:
- Based on the matched intermediate semantic prototypes, Buffaly selects the appropriate standardized clinical entity from the coding ontologies (ICD-10 and SNOMED CT).
- The selected clinical entity includes explicit links to semantic definitions, standardized code values, and provenance details for transparency.
Example Outcome:
- Predicted Clinical Entity:
ClinicalOntology.Cardiomegaly
└── CodeValue =
"I51.7"
└── SNOMED CT ID =
"8186001"
Explanation Provided (Transparent Justification):
- Selected because input tokens precisely matched semantic structures (CardiacSememe + DilatationSememe) defined within intermediate ontology prototypes
This structured workflow ensures Buffaly predictions remain accurate, interpretable, and semantically precise, leveraging its unique neurosymbolic framework for robust, transparent clinical language understanding and mapping.
Advantages of Buffaly’s Neurosymbolic Approach
Buffaly's innovative neurosymbolic approach integrates the interpretability of symbolic reasoning with the adaptability and efficiency of neural networks, particularly through leveraging integrated Large Language Models (LLMs). This fusion provides significant advantages, especially in dynamic, transparent, and scalable clinical informatics.
Transparent Dynamic Learning and Immediate Self-Extension
Buffaly rapidly adapts to new clinical terminology using a streamlined and transparent pipeline. When encountering unfamiliar clinical terms, such as "LVEF" (Left Ventricular Ejection Fraction) or "Dilated Cardiomyopathy," the integrated LLM promptly defines these terms by generating explicit definitions, semantic contexts, and relevant usage examples. These definitions are immediately transformed into symbolic representations using ProtoScript, Buffaly’s high-efficiency scripting language. The resulting ProtoScript code is dynamically compiled into the system at runtime (hot-compilation), eliminating downtime and the need for manual updates.
Example Workflow:
- Clinical Term Detected: "LVEF"
- LLM Definition: "Left Ventricular Ejection Fraction, the percentage of blood pumped from the left ventricle with each heartbeat."
- ProtoScript Generation:
partial prototype LVEFSememe : Sememe {
Children = [LeftSememe, VentricularSememe, EjectionSememe, FractionSememe];
}
partial prototype LVEF : LVEFSememe;
- Immediate System Integration: Instant Availability of "LVEF" in the ontology for clinical analysis and coding.
This rapid self-extension capability enables real-time updates, ensuring Buffaly remains current and accurate without downtime.
White-Box Transparency and Interpretability
Unlike traditional "black-box" neural AI systems, Buffaly emphasizes full transparency and interpretability. Each clinical decision and mapping is accompanied by explicit reasoning steps, captured in detailed "semantic breadcrumb trails." These trails document every step from initial clinical input to final coding output, enhancing clinical trust, regulatory compliance, and auditability.
Example (Dilated Cardiomyopathy):
- Identified Term: "Dilated Cardiomyopathy"
- Semantic Parsing: [Dilated, Cardiomyopathy]
-
Mappings:
- SNOMED CT: ID 195029002
- ICD-10: Code I42.0
- Intermediate Prototype Representation:
partial prototype Dilated_CardiomyopathySememe : Sememe {
Children = [DilatedSememe, CardiomyopathySememe];
}
partial prototype Dilated_Cardiomyopathy : Dilated_CardiomyopathySememe;
- Transparency: Complete documentation of semantic reasoning, clearly linking to standardized medical definitions and clinical guidelines.
Clinicians and auditors can thus precisely trace and verify each decision made by Buffaly, significantly enhancing trust and clinical validation.
Revolutionary Neurosymbolic Integration
Buffaly’s neurosymbolic mechanism substantially advances beyond traditional AI methods. Conventional neural systems typically lack interpretability and require extensive retraining to accommodate new knowledge. By contrast, Buffaly’s approach dynamically integrates new concepts transparently, using symbolic structures enhanced by neural insights.
Key Revolutionary Advantages:
- Real-time Adaptability: Immediate integration of new clinical knowledge without system retraining or downtime.
- Explainability: Transparent decision-making process, enabling complete auditability and clinical validation.
- Reduced Operational Complexity: Eliminates extensive manual ontology updates and complex retraining processes associated with traditional neural methods.
Scalable Ontology Management
Buffaly efficiently manages extensive and diverse ontological resources, including:
- Over 15,000 fully loaded ICD-10-CM codes.
- More than 15,000 general linguistic terms sourced from WordNet and VerbNet.
- Dynamic, incremental loading of SNOMED CT concepts, currently maintaining approximately 10,000-20,000 clinical concepts as needed.
Example ("Cor Bovinum") : Buffaly dynamically loads new clinical terms from SNOMED CT instantly upon encounter, providing immediate clinical relevance:
partial prototype Cor_BovinumSememe : Sememe, ClinicalOntology.Cor_Bovinum {
Children = [CorSememe, BovinumSememe];
}
This scalable and incremental approach ensures optimal performance and manageability, maintaining responsiveness even as ontological complexity and clinical vocabulary continuously expand.
Summary
The integration of symbolic precision and neural flexibility in Buffaly’s neurosymbolic approach provides unprecedented transparency, rapid adaptability, and scalability in medical informatics. By automating dynamic ontology expansion with real-time, interpretable updates, Buffaly delivers unmatched clinical accuracy and operational efficiency, setting a new standard in intelligent clinical resource management.
Core Advantages and Unique Selling Points
Unified Ontology Integration for Enhanced Clinical Insights
Buffaly uniquely consolidates multiple complex ontologies—including ICD-10-CM, SNOMED CT, WordNet, VerbNet, FrameNet, and PropBank—into one coherent, interconnected knowledge graph. Traditional medical and linguistic ontologies are typically managed separately, resulting in fragmented data and cumbersome integration processes. By seamlessly combining these resources, Buffaly enables rapid, precise, and contextually-rich querying across domains.
Example:
When a clinician inputs "enlarged heart," Buffaly instantly parses the clinical phrase, accurately mapping it to ICD-10 code I51.7 and leveraging SNOMED CT’s detailed terms (e.g., Cardiomegaly, Dilated Cardiomyopathy) for enhanced precision. This unified approach significantly streamlines clinical decision-making and improves patient outcomes.
Streamlined Ontology Management with ProtoScript
Buffaly leverages ProtoScript, an efficient ontology representation language, dramatically reducing complexity compared to traditional XML or SQL-based systems. Its concise syntax and dynamic compilation enable real-time updates and rapid deployment, simplifying ontology management for healthcare IT teams.
Rapid Development and Deployment Benefits:
- Real-time ontology updates without system downtime.
- Integration of new clinical terms within minutes rather than weeks.
Example:
Integrating the complete ICD-10-CM ontology (15,000+ codes) into Buffaly required only a single day—substantially faster than conventional integration methods, thus significantly reducing operational overhead.
Revolutionary Neurosymbolic Learning for Continuous Adaptation
Buffaly integrates groundbreaking neurosymbolic learning capabilities by combining Large Language Models (LLMs) with ProtoScript. This enables autonomous ontology expansion, continuous self-updating, and rapid adaptation to emerging clinical knowledge without extensive human oversight.
Key Industry Impacts:
- Immediate incorporation of new medical terminology.
- Continuous enhancement of precision medicine capabilities.
Example: Upon encountering the new clinical abbreviation "LVEF" (Left Ventricular Ejection Fraction), Buffaly automatically consults an LLM, defines and integrates the term transparently within minutes, maintaining traceability and full explainability.
Targeted Advantages for Key Stakeholders
Clinical Researchers and Healthcare Providers
- Enhanced Clinical Precision: Accurate patient classification and resource alignment.
- Real-Time Updates: Automatically incorporates the latest clinical terminologies and coding standards.
Example:
A cardiology research team leverages Buffaly’s precise ontology mappings to rapidly identify patient cohorts, accelerating research cycles and enhancing study accuracy.
Digital Health Innovators and Technology Partners
- Efficient Integration: Quick embedding of Buffaly’s sophisticated semantic capabilities into external health applications.
- Value Enrichment: Significantly enhances user experience and data accuracy in digital health solutions.
Example:
A telehealth platform integrates Buffaly to automatically interpret patient-reported symptoms, translating them accurately into standardized medical codes for improved automated care responses and clinical interactions.
Investors in Healthcare Technology
- Disruptive Innovation: Neurosymbolic learning positions Buffaly as a groundbreaking advancement in healthcare informatics.
- Scalable Market Opportunity: Buffaly’s adaptive capabilities allow rapid expansion into adjacent markets such as precision medicine, clinical analytics, and AI-driven healthcare applications.
Example: Investors recognize the substantial competitive advantage in Buffaly’s capacity for autonomous learning and continuous self-improvement, translating into sustained market differentiation and long-term value creation.
FAQs
Question 1:
How does Buffaly's neurosymbolic approach handle ambiguous or context-sensitive medical terminology, where traditional neural networks typically leverage embeddings for context?
Answer:
Buffaly addresses ambiguity by explicitly encoding contextual meanings through intermediate semantic layers (Clinical Ontology) rather than relying solely on statistical embeddings. Terms are mapped to precise "sememes" that disambiguate context explicitly. For instance, the term "dilatation" is clearly distinguished from "dilation," each semantically and explicitly linked to medical contexts like cardiac dilatation or vascular dilation. Buffaly's approach thus ensures that contextual disambiguation is both explicit and traceable, outperforming embeddings in interpretability without sacrificing accuracy.
Question 2:
Given that Buffaly relies heavily on explicit symbolic representations, how does it scale when encountering entirely new clinical concepts not present in any preloaded ontology?
Answer:
Buffaly utilizes an integrated large language model (LLM) to define and incorporate novel clinical concepts dynamically and transparently. When a new clinical concept (e.g., "Left Ventricular Noncompaction") appears, the LLM rapidly provides structured semantic definitions, which are automatically transformed into ProtoScript prototypes. These prototypes are instantly hot-compiled into Buffaly’s ontology, enabling immediate system-wide integration without retraining or downtime. This capability allows Buffaly to scale dynamically and maintain up-to-date clinical knowledge seamlessly.
Question 3:
Neural networks typically generalize by leveraging continuous vector spaces and latent embeddings. How does Buffaly generalize effectively without these statistical techniques?
Answer:
Buffaly generalizes by structuring explicit, hierarchical semantic relationships rather than using continuous embeddings. Through intermediate prototypes and semantic inheritance (e.g., Cardiomegaly as a parent to Dilated Cardiomyopathy), the system encodes semantic generalizations explicitly. This structured inheritance-based approach achieves generalization transparently and predictably, enabling Buffaly to handle previously unseen phrases by mapping them explicitly through a known semantic hierarchy. Thus, generalization occurs through symbolic inference rather than statistical approximation.
Question 4:
Symbolic AI methods have repeatedly failed to scale effectively in complex domains like medical informatics due to their brittleness and manual ontology engineering overhead. Why is Buffaly’s symbolic representation different, and how does the integration of LLMs fundamentally change this?
Answer:
Traditional symbolic approaches suffered from brittleness because they relied on manually engineered, rigid ontologies that could not adapt dynamically. Buffaly circumvents this limitation by employing a neurosymbolic approach that leverages Large Language Models (LLMs) to dynamically generate and refine semantic representations. Instead of manual ontology updates, LLMs automatically produce structured definitions and semantic prototypes, which are seamlessly integrated in real-time via ProtoScript. This automation significantly reduces brittleness and eliminates manual ontology engineering overhead, enabling symbolic methods to scale adaptively in complex and evolving domains like medical informatics.
Question 5:
Historically, symbolic systems struggled with ambiguity and subtlety in natural language, areas where neural models excel. Can Buffaly's symbolic-based approach truly overcome these traditional limitations, and if not fully, do you see LLMs eventually closing this gap?
Answer:
Buffaly substantially mitigates these limitations through its hybrid approach. While symbolic representations provide precise, interpretable semantics, Buffaly’s integration of LLMs directly addresses ambiguity and language subtlety. LLMs inherently excel at capturing nuanced linguistic variations, providing contextual definitions and semantic relationships that symbolic systems alone traditionally lacked. Thus, Buffaly effectively bridges this gap by combining the clarity of symbolic logic with the linguistic sensitivity of neural models. In the longer term, advances in LLM capabilities may fully close any remaining ambiguity gaps, enabling even more sophisticated neurosymbolic collaboration that combines neural understanding with symbolic precision and interpretability.
Question 6:
Ontologies typically use rigid structures like RDF, OWL, or relational schemas. Why is ProtoScript's Prototype-based approach superior for dynamically integrating diverse medical and linguistic ontologies?
Answer:
Traditional methods like RDF or OWL require explicit, static schemas and struggle to dynamically adapt to new information. ProtoScript’s Prototype-based approach, however, treats ontological elements as flexible, runtime-adaptable structures. Prototypes inherently support multiple inheritance, semantic blending, and runtime reconfiguration, making it seamless to integrate and harmonize diverse ontologies like ICD-10, SNOMED CT, WordNet, and clinical terminologies. This flexibility allows Buffaly to incrementally and dynamically expand the ontology, reflecting real-world complexities and continuous medical knowledge evolution, something rigid schema-based approaches cannot easily achieve.
Question 7:
ProtoScript has been discussed primarily in terms of ontology representation. How does its nature as a programming language—complete with executable functions and C# interoperability—add significant advantages over pure data specification languages (e.g., XML, RDF)?
Answer:
ProtoScript isn't merely a static specification for ontological data; it's a fully capable programming language with executable logic, methods, inheritance, and rich integration capabilities. Unlike XML or RDF, which can only describe data structures, ProtoScript prototypes can include functional behaviors, dynamic operations, and complex logic directly within the ontology definitions themselves. Furthermore, ProtoScript seamlessly interfaces with C#, enabling the invocation of external libraries, complex business logic, or algorithmic code directly from within prototypes. Conversely, C# applications can dynamically instantiate, manipulate, and execute ProtoScript-defined ontological structures. This powerful two-way integration significantly enhances flexibility, enabling dynamic ontology adaptation, real-time semantic reasoning, and interactive workflows unattainable with traditional data-only ontology representations.