

"There is a belief that learning to compress well will lead to intelligence. Recently, language modeling has been shown to be equivalent to compression, which offers a compelling rationale for the success of large language models (LLMs): the development of more advanced language models is essentially enhancing compression which facilitates intelligence. Despite such appealing discussions, little empirical evidence is present for the interplay between compression and intelligence. In this work, we examine their relationship in the context of LLMs, treating LLMs as data compressors."
Source
This paper tries to correlate two metrics:
- Performance on "average benchmark scores" as "Intelligence;"
- Ability to compress language.
The first metric is self explanatory. The second is much more difficult to understand. How do we measure a LLM's ability to compress language?
- The authors propose using the bit's per character and propose the formula:
"Intuitively, we seek to utilize pmodel(x) to encode rare sequences with more bits and the frequent ones with fewer bits."
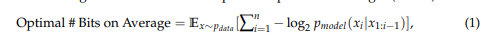
Due to the variety of tokenizers employed by different LLMs, the average bits per token are not directly comparable. Therefore, we utilize the average bits per character (BPC) as the metric.
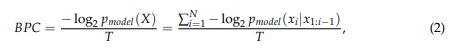
But the question remains: how do we know the "bits" per character for a LLM? It's not like this a readily available by examining the generated text. What are the authors talking about.
We need a bit more context here. Let's look at an earlier paper that developed this idea more:
Language Modeling Is Compression
from Google Deepmind and Meta AI
The core idea behind this paper is to combine language models with a statistical compression algorithm.
LLMZip: Lossless Text Compression using Large Language Models
at ARXIV
This paper gives a better description:
- We start with a piece of text like
- My first attempt at writing a book
- We use the first 5 words (or tokens) to try to predict the next:

- The correct term is at 0, we store that value = 0
- Then we move forward one word:
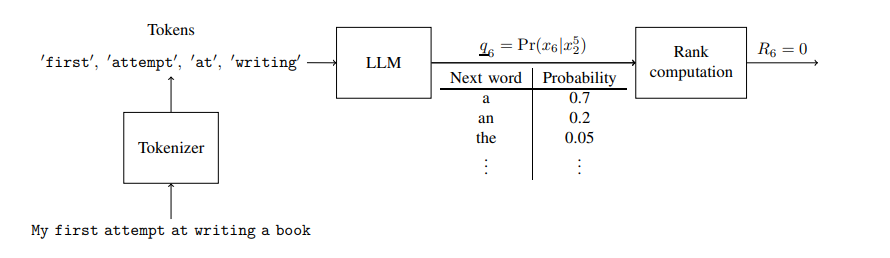
- The correct term is at 0, we store that value = 0
After we repeat this process over and over we will have a string of indexes:[1, 0, 0, 0, 2, 5, 1, etc]as a simple example. Those sequences are fed into a compression algorithm:
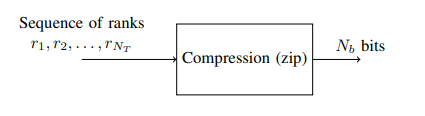
What does this mean?
- A perfect LLM will always predict the next word with perfect accuracy
- The indexes will always be 0
- [0, 0, 0, 0, 0, 0, .... ]
- This array of indexes can be compressed maximally giving a the smallest compression.
Let's say that we have 10 words, all predicted perfectly:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]We can compress that by saying
10 x [0]Giving us an incredibly small compression. Bits < Words
On the other hand
- A terrible LLM will do a terrible job predicting [1001, 3425, 83847, 923838, etc]
- These values will be incredibly hard to compress without loss
- The bits will not be much less than the original string itself. Bits = Words
Who cares about any of this?
- There is an old idea in AI that compression is intelligence, or, at least, highly correlates with intelligence.
- Claude Shannon introduced Information Theory and published much about compressing the English language efficiently.
- Kolmogorov Complexity. In the 1960s, Andrei Kolmogorov and Gregory Chaitin developed concepts around the complexity of a string defined as the length of the shortest possible description of that string within a fixed computational model. This idea suggests that the more you can compress a dataset (i.e., the shorter the description), the more you understand the underlying patterns and structure of the data.
Consider the following two strings of 32 lowercase letters and digits:
abababababababababababababababab, and[
1001, 3425, 83847, 923838, etc]
function GenerateString2() return "4c1j5b2p0cv4w1x8rx2y39umgw5q85s7"
function GenerateString1()
return "ab" × 16
Why this may or may not be a reasoned argument.
- As a thought experiment, let's assume that we have a giant database, of every sentence every written.
- Compression of any sentence now becomes a single digit number
There is no intelligence, only memorization. But awesome compression.