




In the tech industry today, we frequently toss around sophisticated terms like "ontology" , often treating them like magic words that instantly confer depth and meaning. Product managers, software engineers, data scientists—everyone seems eager to invoke "ontology" to sound informed or innovative. But if you press most practitioners, even seasoned experts, to explain precisely what they mean by ontology, you'll often find vague descriptions, confused analogies, or a hasty pivot to safer ground.
The term
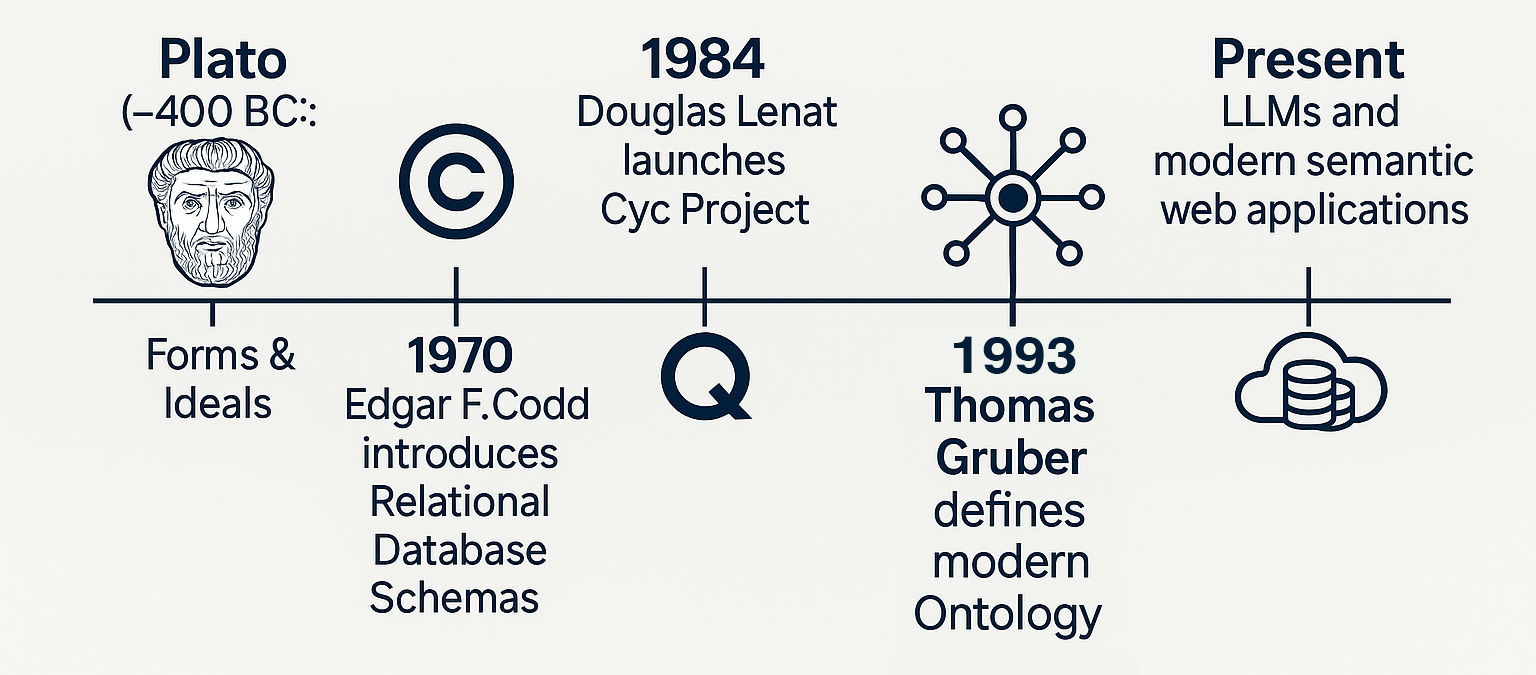
ontology
itself is burdened with centuries of philosophical baggage, stretching all the way back to Plato's ideals—the notion of perfect "prototypes" or abstract forms from which real-world examples are derived. But in modern computer science and artificial intelligence, the use of the word ontology typically traces its lineage to a seminal 1993 paper by Thomas R. Gruber:
"Toward Principles for the Design of Ontologies Used for Knowledge Sharing."
Ironically, although Gruber's paper is widely cited and nominally respected, in practice almost nobody strictly adheres to its original insights or foundational principles. Instead, many contemporary practitioners have drifted away from the original intent, treating ontologies as just another synonym for data schemas or knowledge graphs, sometimes even conflating them entirely with static relational database models.
This casual approach obscures a deeper understanding. To clarify what an ontology truly is—especially in the computational sense—let's step back and return to the foundational source. What exactly did Gruber define as an ontology? What were his guiding principles, and why do we often overlook them in practice?
By revisiting these fundamental ideas and principles, we can clarify the confusion, reclaim some semantic rigor, and perhaps rediscover what makes ontologies uniquely powerful tools for knowledge representation—beyond mere buzzwords. Let's begin by going back to the roots.
From First Principles: Why Create an Ontology?
An idea must be clear and intuitive, or else it risks hiding flawed assumptions beneath layers of complexity. Let’s step back from formal definitions for a moment and approach ontology from a first-principles perspective: Why do we even need an ontology in the first place?
In the early 1990s, the research community was already deeply exploring artificial agents—independent systems capable of reasoning, learning, and communicating. One fundamental challenge quickly emerged: different agents, designed by different organizations with distinct implementations, often needed to communicate about shared ideas. Yet their internal representations frequently differed significantly, causing confusion and misalignment in interactions.
Imagine a scenario today: your insurance provider and your doctor’s electronic health record system need to exchange information about COVID-19. What exactly does "COVID-19" mean? Does it refer to the disease, SARS-CoV-2 infection? Is it the virus itself? Could it represent specific symptoms, like loss of taste and smell, or simply the positive result of a PCR test? Without a shared understanding, information exchange quickly becomes ambiguous and error-prone.
An ontology addresses precisely this kind of ambiguity by creating a common semantic layer . Semantics, simply put, means meaning. An ontology explicitly defines what things mean in a domain, providing clarity that transcends differences in individual system implementations. From this perspective, ontologies become incredibly powerful because they provide a shared language—a universal way to clearly represent meaning.
When we explicitly ask, "What is a patient?" , we aren’t concerned with how a patient is represented within a particular database, data structure, or software implementation. Instead, we are interested in the fundamental idea: a patient is a human being receiving medical care, who may have symptoms, diagnoses, treatments, or medical history. Likewise, when we say "disease," we're defining precisely what that term means in a way that all systems can understand and agree upon. A disease might be explicitly defined as a medical condition characterized by a specific set of symptoms, an identifiable cause, or a known pathology.
This explicit semantic definition allows all interacting systems—whether your hospital’s clinical software, your insurance company's claims database, or a government health authority—to operate from the same conceptual foundation.
Going deeper into implementation details, when we talk about a "patient," we don't care about the particular technical representation (e.g., which database schema, file format, or programming language). Instead, we define and describe the concept itself clearly and consistently: what attributes or properties characterize a patient, how patients relate to other concepts like symptoms, diseases, diagnoses, or treatments, and precisely what roles these entities play within a broader domain.
This explicit, clear, and agreed-upon semantic layer provides a critical foundation for data interoperability, meaningful communication, and shared reasoning between diverse and independent software systems. At its core, this ability to represent meaning precisely and consistently is exactly what makes ontologies so valuable—and indeed, indispensable—in complex domains like healthcare.
The ontology is the semantic layer. The word semantic, literally means “meaning”. An ontology is a structured representation of meaning.
Ontologies vs. Schemas vs. Knowledge Graphs: Clarifying the Differences
Before moving forward, it's crucial to clearly differentiate ontologies from related, often-confused concepts such as database schemas and knowledge graphs. Although these terms frequently appear together in conversations about data representation and semantics, each serves a fundamentally distinct purpose and provides unique capabilities.
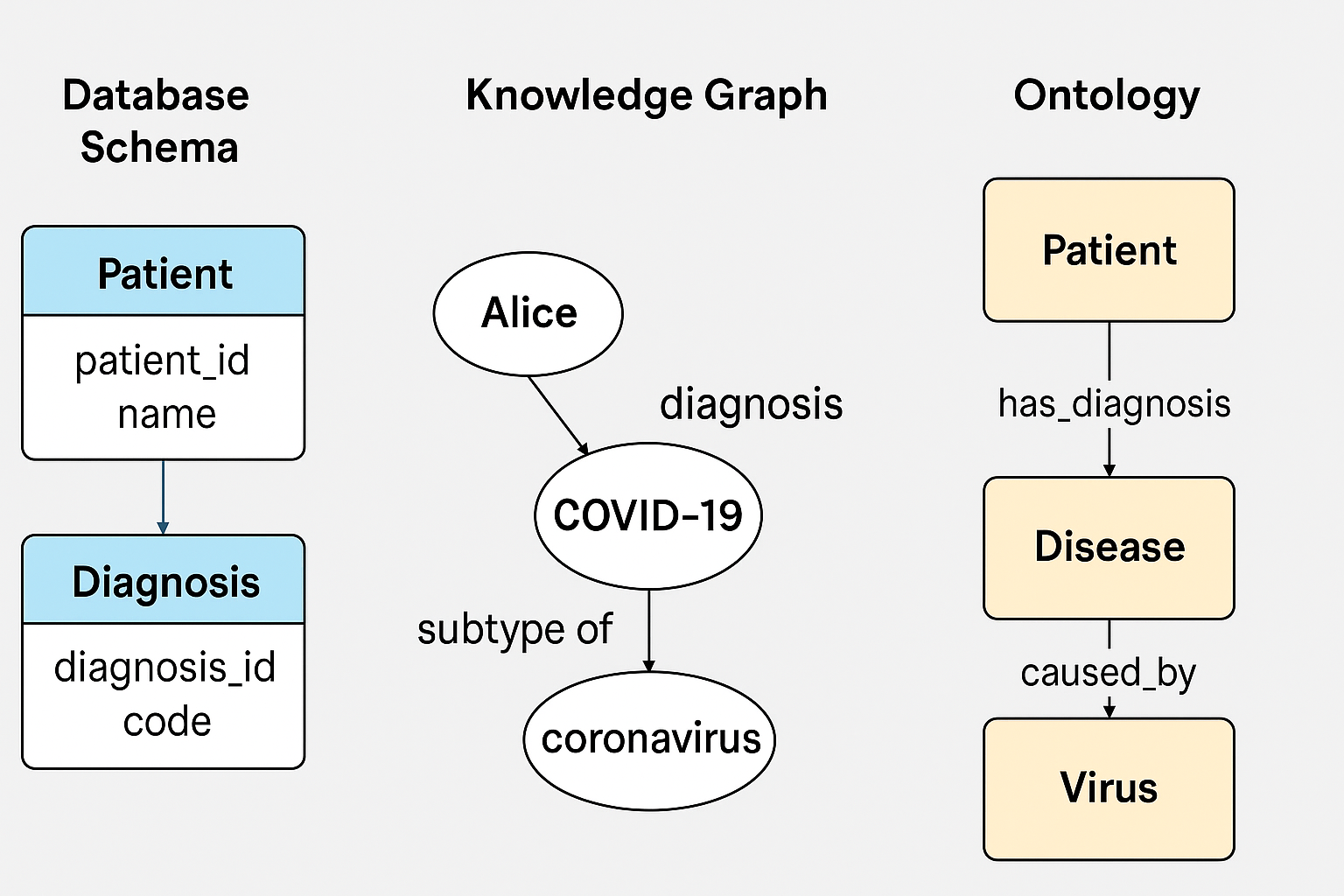
Database Schemas: Structure without Semantics
A database schema defines the structure, format, and relationships of data in databases. It typically focuses on tables, columns, data types, and keys. Schemas help ensure data integrity and provide a clear organizational structure for data storage and retrieval. However, schemas do not explicitly represent the meaning of the data—they simply define how data is physically structured and stored.
Consider this simplified example of a database schema for medical records:
CREATE TABLE Patient (
patient_id INT PRIMARY KEY,
first_name VARCHAR(
50
),
last_name VARCHAR(
50
),
date_of_birth DATE
);
CREATE TABLE Diagnosis (
diagnosis_id INT PRIMARY KEY,
patient_id INT,
diagnosis_code VARCHAR(
20
),
diagnosis_date DATE,
FOREIGN KEY (patient_id) REFERENCES Patient(patient_id)
);
In this schema, data relationships are clearly defined (e.g., diagnoses linked to patients), but the schema does not explicitly encode the meaning of "patient," "diagnosis," or "diagnosis_code." So what's missing?
A schema is an implementation. The patient is represented across multiple tables, foreign keys, and columns. It's not a coherent semantic entity with relationships to other coherent semantic entities. Relationships are limited to one-to-one, or one to many. There's no inheritance. There's no complexity. There's no data, just schema.
Knowledge Graphs: Connectivity and Basic Meaning
A knowledge graph, on the other hand, explicitly encodes relationships among entities, typically in a flexible, graph-based structure. Knowledge graphs often use standardized vocabularies (like RDF) to represent data as a network of entities (nodes) connected by relationships (edges). Knowledge graphs are a lot closer to ontologies. I would argue that 95% of practitioners today conflate knowledge graphs with ontologies – for good reason.
Consider a simplified knowledge graph representation of medical data:
@prefix ex:
<http://example.org/>
.
ex
:Patient123 a ex:Patient ;
ex:firstName
"John"
;
ex:lastName
"Doe"
;
ex:hasDiagnosis ex:Diagnosis456 .
ex
:Diagnosis456 a ex:Diagnosis ;
ex:diagnosisCode
"U07.1"
;
ex:diagnosisDate
"2023-02-10"
^^xsd:date .
Here, meaning is partially explicit—relationships like "hasDiagnosis" clearly connect entities—but the precise meaning of "Patient," "Diagnosis," or "U07.1" remains informal and loosely defined. There's no clear semantic definition ensuring that systems interpret these concepts consistently. Knowledge graphs provide flexibility and connectivity, but often lack rigorous semantic clarity or reasoning capabilities.
Ontologies: Explicit Semantic Definitions and Logical Reasoning
In contrast, ontologies explicitly define concepts, their meanings, and how they relate in formal, rigorous ways. Ontologies explicitly encode semantic meaning and constraints, allowing software systems to reason and infer new knowledge directly.
Consider a simplified ontology representation (using OWL) of the same scenario:
@prefix :
<http://example.org/>
.
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
:Patient a owl:Class ;
rdfs:label "Patient" ;
rdfs:subClassOf [
a owl:Restriction ;
owl:onProperty :hasDiagnosis ;
owl:someValuesFrom :Diagnosis
] .
:Diagnosis a owl:Class ;
rdfs:label "Diagnosis" ;
rdfs:subClassOf [
a owl:Restriction ;
owl:onProperty :diagnosisCode ;
owl:exactly 1 ;
owl:allValuesFrom xsd:string
] .
:COVID19Diagnosis a owl:Class ;
rdfs:subClassOf :Diagnosis ;
owl:equivalentClass [
a owl:Restriction ;
owl:onProperty :diagnosisCode ;
owl:hasValue "U07.1"
] .
Here, concepts ("Patient," "Diagnosis," "COVID-19 Diagnosis") and relationships are explicitly defined with semantic clarity and logical constraints. The ontology precisely defines what a patient and diagnosis mean, specifies their logical structure, and includes reasoning constraints—for example, explicitly defining "COVID19Diagnosis" as equivalent to having the diagnosis code "U07.1."
The power of ontologies is that their meaning is explicit and formally defined. They enable consistent interpretation, automated reasoning, and knowledge validation. Unlike schemas, ontologies clearly define semantic meaning rather than just data structure. Unlike knowledge graphs, ontologies rigorously encode meaning, constraints, and inference rules rather than simply relationships.
Summary of Differences
By understanding these distinctions clearly, we can appreciate precisely what ontologies offer: explicit semantic clarity, formal reasoning, and rigorous definition of meaning, which goes significantly beyond what schemas or knowledge graphs alone can provide.
SNOMED CT and OWL: Real-world Ontologies in Practice
The concept of an ontology often seems abstract and theoretical—so let’s ground our discussion in a tangible example. One of the most widely adopted and practical ontologies today is the Systematized Nomenclature of Medicine — Clinical Terms (SNOMED CT) . Developed specifically for healthcare, SNOMED CT provides a standardized vocabulary that defines diseases, symptoms, procedures, drugs, and clinical findings clearly and consistently, facilitating data exchange and semantic interoperability across health systems globally.
SNOMED CT isn't just a structured vocabulary; it's built explicitly as an ontology. That means it formally defines concepts and their relationships, enabling precise meaning and semantic clarity. For example, SNOMED CT might explicitly represent the disease "COVID-19 pneumonia" as follows (simplified example):
# SNOMED CT Example (simplified, OWL/Turtle format)
:COVID19Pneumonia rdf:type owl:Class ;
rdfs:label
"COVID-19 Pneumonia"
;
rdfs:subClassOf :ViralPneumonia ;
rdfs:subClassOf [
rdf:type owl:Restriction ;
owl:onProperty :hasCausativeAgent ;
owl:someValuesFrom :SARSCoV2Virus
] ;
rdfs:subClassOf [
rdf:type owl:Restriction ;
owl:onProperty :associatedMorphology ;
owl:someValuesFrom :PneumonicInflammation
]
Here, "COVID-19 pneumonia" is explicitly defined as a subclass of "Viral Pneumonia," explicitly caused by "SARS-CoV-2 Virus," and explicitly associated with "Pneumonic Inflammation." SNOMED uses subclass relationships (rdfs:subClassOf) and existential restrictions (owl:someValuesFrom)—OWL constructs designed for semantic clarity and reasoning.
OWL (Web Ontology Language) —and its successor OWL 2 —is the primary standard adopted for formally expressing ontologies such as SNOMED CT. OWL was specifically designed to enable clear semantic definitions, consistency checking, and automated reasoning about concepts and their relationships. OWL is built upon RDF (Resource Description Framework), providing formal logical constructs like subclassing, existential restrictions, universal quantification, and property constraints.
An OWL ontology explicitly declares entities (classes), their properties, and logical constraints about these entities. For example, in OWL, we might define a general concept such as "Patient":
# OWL Definition
of
a Patient (simplified example)
:Patient rdf:type owl:Class ;
rdfs:label
"Patient"
;
rdfs:subClassOf [
rdf:type owl:Restriction ;
owl:onProperty :hasDiagnosis ;
owl:someValuesFrom :Disease
] ;
rdfs:subClassOf [
rdf:type owl:Restriction ;
owl:onProperty :receivesTreatment ;
owl:someValuesFrom :Treatment
] .
Here, a "Patient" is explicitly defined as someone who "has at least one diagnosis" and "receives at least one treatment," leveraging OWL constructs explicitly designed for precise semantic meaning and consistency.
Ontologies as Logical Systems: More Than Just Data Representation
Gruber's original vision for ontologies wasn't just semantic clarity and data exchange—it explicitly included logical reasoning capabilities. Ontologies were not intended merely as passive definitions of terms but as active logical systems capable of automatically generating and validating new knowledge.
The reasoning capabilities envisioned for ontologies included:
-
Subclass reasoning (Inheritance):
Automatically categorizing instances based on their properties and relationships.
-
Existential restrictions:
Defining concepts explicitly by requiring certain relationships to exist.
-
Logical conjunctions:
Explicitly combining multiple conditions logically to define complex concepts.
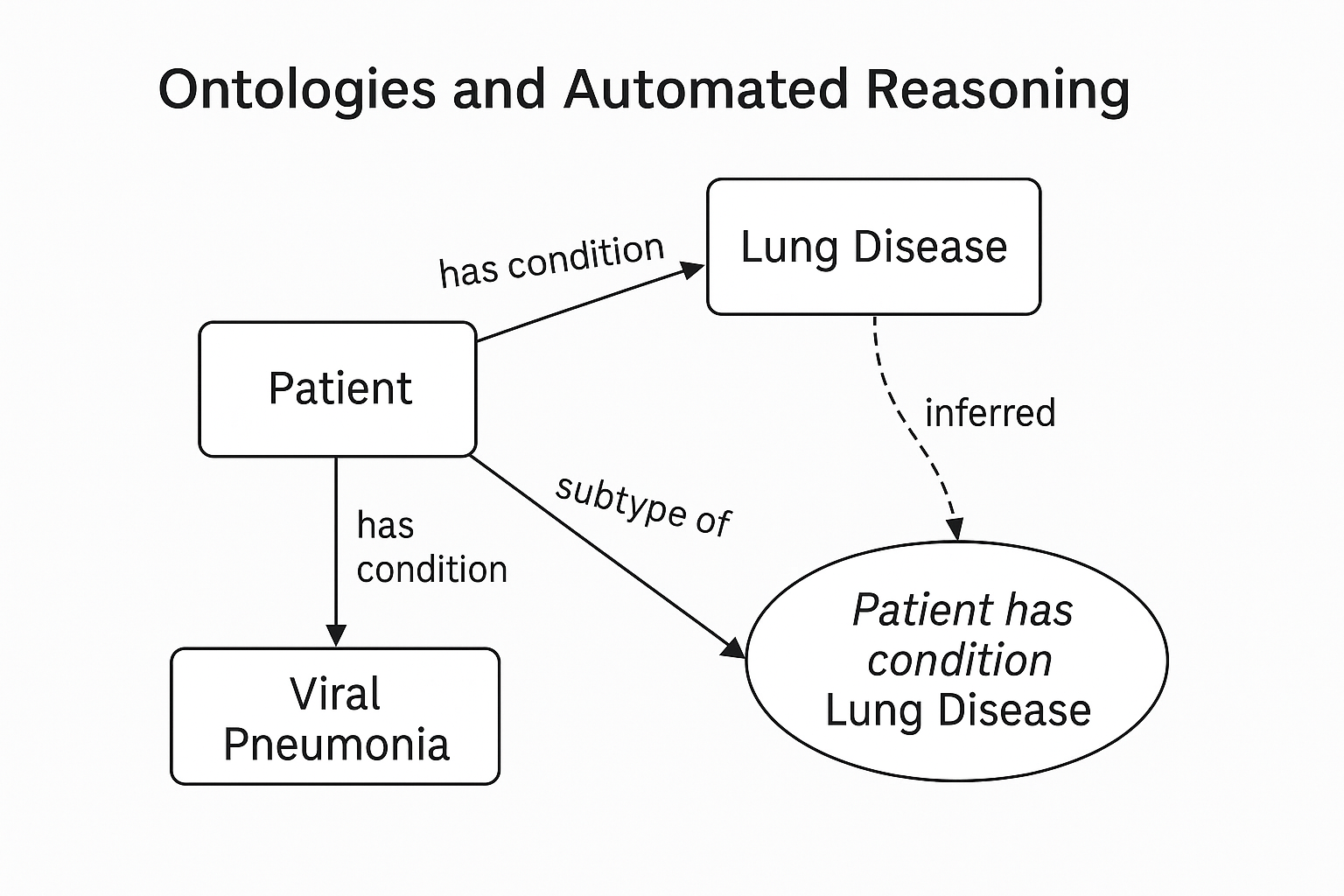
Consider an illustrative OWL example of these constructs in practice:
# OWL Logical Example: Defining a
"HighRiskPatient"
:HighRiskPatient rdf:type owl:Class ;
owl:equivalentClass [
rdf:type owl:Class ;
owl:intersectionOf (
:Patient
[ rdf:type owl:Restriction ;
owl:onProperty :hasDiagnosis ;
owl:someValuesFrom :ChronicDisease ]
[ rdf:type owl:Restriction ;
owl:onProperty :ageInYears ;
owl:someValuesFrom [
rdf:type rdfs:Datatype ;
owl:onDatatype xsd:integer ;
owl:withRestrictions ( [ xsd:minInclusive
65
] )
]
]
)
] .
Here, we explicitly define a "High-Risk Patient" logically: someone who is a "Patient," who has at least one chronic disease, and whose age is 65 or older. OWL-based reasoning engines can automatically classify individual patient records according to these logical definitions, ensuring consistency and supporting advanced inference.
The powerful vision behind OWL was that such logical reasoning and inference would become a core part of everyday ontology use, enabling automated knowledge validation, advanced semantic interoperability, and complex inference chains in real-world scenarios.
Practical Reality: What Actually Happens in Large Ontologies Like SNOMED CT
However, despite this ambitious vision, the reality of implementing full logical reasoning in large-scale ontologies such as SNOMED CT quickly diverged from theoretical ideals. The computational complexity of advanced logical inference increases rapidly as ontology size grows. With hundreds of thousands of concepts and relationships, ontologies like SNOMED CT typically constrain or simplify the complexity of logical constructs used.
In practice, SNOMED CT leverages a subset of OWL constructs—primarily simple subclass hierarchies and existential restrictions—to ensure semantic consistency, clear definitions, and basic reasoning:
-
Commonly used in SNOMED CT
:
-
Subclass-superclass hierarchies (Inheritance)
-
Existential restrictions (e.g., specifying at least one causative agent or associated symptom)
-
Subclass-superclass hierarchies (Inheritance)
-
Rarely or minimally used in practice
:
-
Complex logical conjunctions (extensive combinations of conditions)
-
Universal quantification (owl:allValuesFrom)
-
Cardinality restrictions (precisely how many instances of relationships exist)
-
Advanced datatype restrictions (e.g., complex numeric constraints)
-
Complex logical conjunctions (extensive combinations of conditions)
This selective adoption of OWL features is not due to conceptual disagreements but simply reflects pragmatic concerns—performance, maintainability, computational feasibility, and ease of use at scale.
For example, instead of encoding complex logical rules directly in the ontology, real-world systems often implement advanced reasoning externally, through programming languages or specialized inference engines. Developers commonly push more complex logic—such as clinical guidelines or multi-factor classification logic—to software layers built with languages like Java, Python, or C#, leaving the ontology itself to maintain simpler, more manageable semantic definitions.
Real-world Implications: Where We Stand Today
As a result, today's practical implementations of large ontologies like SNOMED CT typically serve as robust semantic vocabularies rather than as comprehensive logical reasoning engines. They maintain clear, standardized definitions that facilitate interoperability and basic classification, but usually leave advanced logical inference outside the ontology.
In short, although Gruber and OWL envisioned a powerful semantic reasoning framework deeply embedded within the ontology, practical realities of implementation and performance constraints mean we leverage a simpler, pragmatic subset of this vision. Ontologies today remain incredibly valuable semantic foundations—but their ambitious original promise as fully integrated logical inference systems is often realized partially or externally in software engineering practices outside the ontology itself.
This understanding provides valuable context: even as we continue to strive for clarity, interoperability, and semantic meaning, we remain aware that practical limitations have shaped the way ontologies are implemented and used in reality.
Ontologies in the Era of Large Language Models (LLMs)
Today, the technology landscape is dominated by powerful language models like GPT-4, Gemini, and others. These large language models (LLMs) have become incredibly effective at capturing and generating human language, seemingly "understanding" context and meaning in ways we previously thought impossible. Yet, their remarkable success also brings a new challenge: the black box problem .
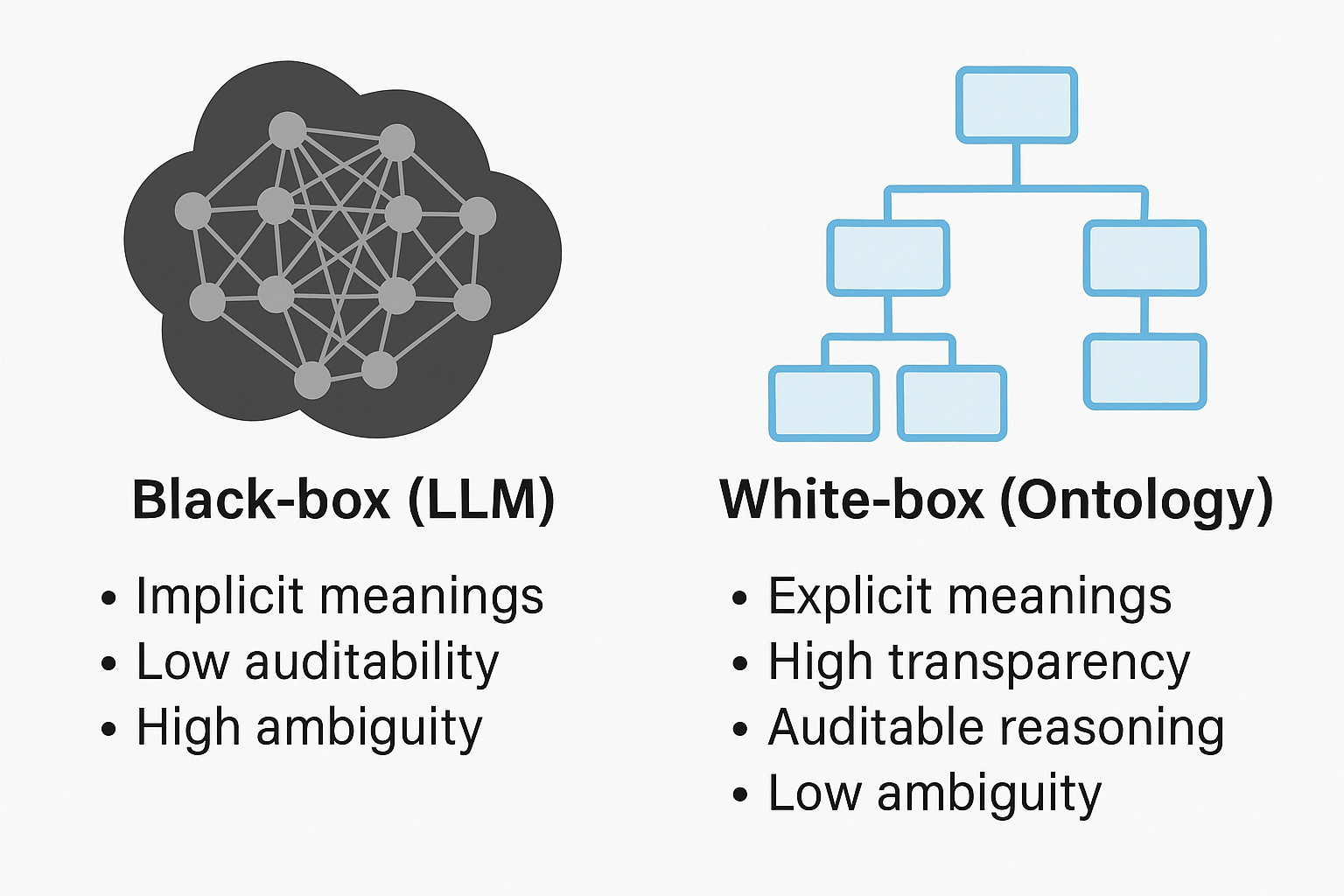
At their core, LLMs represent meaning using high-dimensional, distributed representations—millions or billions of parameters encoding subtle statistical relationships learned from vast amounts of text. While this distributed representation provides flexibility, generalization, and powerful pattern-matching abilities, it is inherently opaque. The meaning itself is not stored explicitly, but rather implicitly, spread across a vast network of weights. As a result, it is nearly impossible to trace exactly why an LLM produces a particular answer or inference.
This opacity leads directly to unpredictability and to what is commonly called "hallucinations": the tendency of these models to produce plausible-sounding but entirely incorrect or unsupported information. Distributed representations inherently rely on probabilistic associations, not explicit semantic definitions. This makes them prone to subtle and unpredictable errors that are difficult—often impossible—to trace or correct.
By contrast, ontologies occupy the exact opposite position on the spectrum of meaning representation. Ontologies are, by definition, explicit , transparent , and "white-box" . They define meanings clearly and explicitly, providing unambiguous representations of concepts and relationships. If an ontology says explicitly that "COVID-19 pneumonia is a type of viral pneumonia caused by the SARS-CoV-2 virus," this definition is precisely captured and traceable. There is no ambiguity in interpretation. Ontologies clearly delineate what is known, how concepts relate, and how inferences can be drawn explicitly from logical definitions.
Yet, this clarity comes with trade-offs. Ontologies typically lack the flexibility, generalization, and pattern-completion capabilities that distributed representations provide. They are rigid in the sense that new concepts or subtle variations in meaning often require deliberate extension or redesign. But this same rigidity is precisely what makes them reliable, predictable, and suitable for applications where ambiguity or error cannot be tolerated.
Nowhere is this clearer than in healthcare . In medical settings, ambiguous meanings or incorrect inferences can lead to serious consequences for patient safety, legal compliance, and clinical decision-making. The precision and clarity of an ontology like SNOMED CT directly address these requirements. Medical data representations must not only be explicit and correct—they must also include an audit trail. Ontologies naturally provide this auditability because every inference is explicitly defined and traceable. The exact logic leading to a classification or conclusion can be inspected, verified, and justified in detail.
Thus, ontologies represent a valuable complement—even perhaps an antidote—to some of the problems inherent in large language models. By clearly defining semantic meaning and explicitly structuring knowledge, ontologies can help mitigate ambiguity, reduce hallucinations, and provide a robust framework for reliable and explainable reasoning.
This perspective brings us full circle to Gruber's original vision: semantic clarity, explicit representation, logical inference, and traceable reasoning. As powerful as LLMs are for broad and flexible applications, the continued relevance—even the increased importance—of explicit semantic representations offered by ontologies cannot be understated. Ontologies are not simply academic curiosities; they are essential tools for domains where precision, transparency, and auditability matter most. In the emerging landscape shaped by powerful but opaque language models, ontologies have regained importance as critical instruments for clarity, transparency, and semantic rigor.
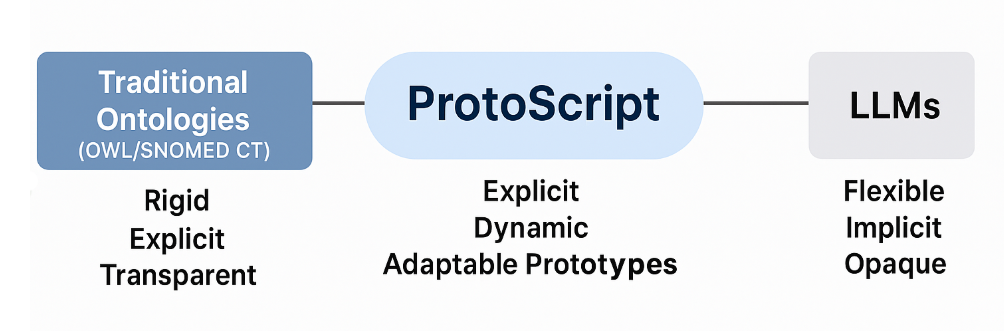
ProtoScript: Bridging Semantic Clarity and Flexibility
We've seen that ontologies offer something uniquely valuable—explicit semantic clarity, transparency, and traceable reasoning—but they also introduce practical limitations in complexity, scalability, and adaptability. Meanwhile, large language models (LLMs) provide unmatched flexibility, generalization, and fluidity, but at the cost of semantic opacity and unpredictability.
Is there a middle ground—one that captures the explicit semantic clarity and transparent reasoning of ontologies, while still offering dynamic flexibility and ease of adaptation more reminiscent of modern, distributed systems?
This brings us to a new approach, called ProtoScript:
"ProtoScript is a graph-based ontology representation framework built around dynamic prototypes rather than rigid classes. It combines the flexibility of prototype-based programming with the semantic clarity of ontologies, allowing entities to inherit dynamically from multiple parents, evolve at runtime, and generate new categorization structures spontaneously through instance comparisons. Instead of relying solely on formal logical axioms, ProtoScript emphasizes practical, lightweight reasoning using Least General Generalizations (LGG) and subtyping operators, making it easier to adapt, scale, and maintain complex knowledge bases. If your ontology needs rapid evolution , flexibility , and real-time generalization from actual data—especially for domains with changing or uncertain conceptualizations— ProtoScript offers a uniquely powerful approach over traditional systems like OWL or RDF Schema, which are more static, strictly formal, and labor-intensive to adapt."
Traditional ontology systems—such as OWL-based systems like SNOMED CT—are inherently structured around rigid, static classes and strict logical constraints. This rigidity provides excellent semantic clarity, but at the cost of adaptability and ease of maintenance. Even modest conceptual changes often require extensive manual redesign or costly ontology engineering.
In contrast, ProtoScript rethinks the ontology paradigm by using dynamic, flexible prototypes as core entities. Instead of static classes, ProtoScript's prototypes are fluid structures capable of dynamically inheriting from multiple parents and adapting their definitions at runtime. This inherently flexible structure greatly reduces complexity and rigidity, making the ontology itself easier to evolve organically as concepts change.
Moreover, traditional ontologies embed complex logical axioms directly into their core structure, leading to computational complexity and scalability limitations. ProtoScript instead leverages:
- Traditional programming syntax. Directly embeddable within the ontology. This lets us have the power of object-oriented programming within the ontology itself. It's clear, more natural for a programmer, and more expressive than the traditional logic found with in ontologies.
- Ad-hoc, lightweight reasoning through intuitive categorization mechanisms such as Least General Generalization (LGG). Rather than relying exclusively on complex axioms, ProtoScript generalizes and categorizes concepts based directly on actual instance comparisons—using tangible examples to spontaneously form new generalizations and categories.
Practically, this means ProtoScript maintains semantic clarity and explicit reasoning (just like OWL or SNOMED CT) but provides far more adaptability, scalability, and ease of implementation. In domains such as healthcare—where definitions, guidelines, and conceptual understandings evolve rapidly (e.g., COVID-19)—ProtoScript's dynamic ontology structure allows real-time updates, transparent reasoning paths, and clear semantic traceability. The result is a system uniquely positioned to maintain auditability and accuracy without sacrificing flexibility.
ProtoScript's approach, therefore, provides an intriguing middle ground. It retains the essential strengths of ontologies—explicit meaning, semantic rigor, and clear reasoning—while explicitly addressing their most critical weaknesses: rigidity, complexity, and limited adaptability.
Exploring ProtoScript's unique approach and practical implications in detail warrants a separate, dedicated treatment. For now, we've introduced it here as a promising direction—one we hope to explore further in subsequent discussions. ProtoScript offers a compelling potential solution to the semantic challenges of the modern knowledge landscape, blending the clarity of explicit semantic representation with the adaptability and responsiveness demanded by today's rapidly evolving domains.
Conclusion: Toward a Clearer Path for Knowledge Representation
The term "ontology" is widely used but often misunderstood. At its core, as introduced by Gruber, an ontology explicitly defines shared conceptualizations to allow unambiguous communication between heterogeneous systems. While traditional ontologies—such as SNOMED CT implemented with OWL—provide clear, explicit definitions, practical challenges and computational complexities have led practitioners to simplify or externalize logical reasoning from the ontology itself.
Meanwhile, large language models offer powerful, flexible reasoning capabilities, yet their distributed representation inherently lacks transparency, auditability, and explicit semantic clarity, introducing significant risks in sensitive domains such as healthcare.
ProtoScript suggests a promising approach: blending the explicit semantic rigor of traditional ontologies with the flexibility and dynamic adaptability reminiscent of modern computational methods. Rather than static classes and complex axioms, ProtoScript employs dynamic prototypes, lightweight reasoning, and intuitive categorization—potentially addressing the weaknesses of both ontologies and LLMs.
In today's rapidly evolving information landscape, explicitly capturing and reasoning about meaning remains crucial, especially when ambiguity and unpredictability cannot be tolerated. Ontologies continue to deserve special attention—perhaps now more than ever—as we seek transparent, robust methods for representing knowledge clearly and reliably.
In future discussions, we'll explore in greater depth how ProtoScript, and approaches like it, might practically bridge the gap between rigorous semantics and flexible adaptability, ensuring our knowledge systems remain trustworthy, auditable, and resilient to ambiguity.