
























There are three documents the AI industry uses to talk about cost: benchmarks, launch posts, and pricing pages. Not one of them will tell you what your agents actually cost to run. Build your cost model on vendor paper and you inherit the gap between their story and your reality. That gap never shows up as a line item. It shows up as a bill that grows faster than your business does.
At Intelligence Factory, we refuse to run blind. Every workflow we deploy is instrumented end to end. Every message, every tool call, and every token is logged on our own infrastructure and measured against the work it produced. When we recently turned that telemetry loose on a set of production agent tasks, it surfaced three results no pricing page would have predicted:
- We evicted 40.2% of eligible tool context, a substantial volume, without changing a single business outcome.
- We rerouted heavy workloads to a local model during a quota crunch and cut costs on those tasks by roughly 47%, with zero user-facing disruption.
- We benchmarked a newly released “more efficient” flagship model against our real workloads, found it burned 10% more tokens than its predecessor, and declined the upgrade.
None of these wins came from a clever prompt. Each was earned by a structural decision made long before we measured anything. So before the receipts, the architecture that made them possible.
The Three Pillars
We don't treat AI pipelines as black boxes, and we won't build our business at the mercy of any single lab's infrastructure. Three rules govern everything we deploy.
1. Absolute provider agility. No workflow is married to a vendor. Every pipeline can switch models and providers at a moment's notice, driven by real-time economics, latency, or quota pressure, never by a migration project.
2. Complete data sovereignty. We never surrender state to the labs. Every message, tool call, and scrap of conversational history lives on our own servers. Because we own the state, we can open a conversation on OpenAI, hand it to Ollama mid-stream, and close it out on Gemini without losing a single data point.
3. Materialized token streams. Once an agent has learned a process, paying a model to re-reason through it on every run is pure waste. Our Buffaly technology converts those repetitive token streams into deterministic code that skips model inference entirely, typically cutting token costs by 80% on suitable workflows. (You can watch the mechanism at work in our FairPath learning-session demonstration.)
The pillars protect our margins over the long term. The telemetry shows what they earn week to week, in live production. Here are three receipts.
Win 1: Stop Paying Rent on Dead Context
Long-running agent workflows accumulate weight. A database call returns a sprawling JSON payload. A research agent pulls in pages of source material. The agent genuinely needs that raw data for a turn or two. Then it just lingers: ballast that most systems dutifully resend to the model on every subsequent turn. You aren't billed for that data once. You pay rent on it for the rest of the conversation.
Because we own our conversation state (Pillar 2), we could build the direct fix: incremental tool-context eviction. Raw tool results stay intact while the agent is actively reasoning over them. The moment the necessary facts have been extracted, the bulky payloads are progressively evicted from the context window, leaving behind only the summaries needed to finish the job.
Measured across 2,579 production rows:
A substantial volume of estimated tokens evicted: 40.2% of all eligible tool context, with identical business outcomes.
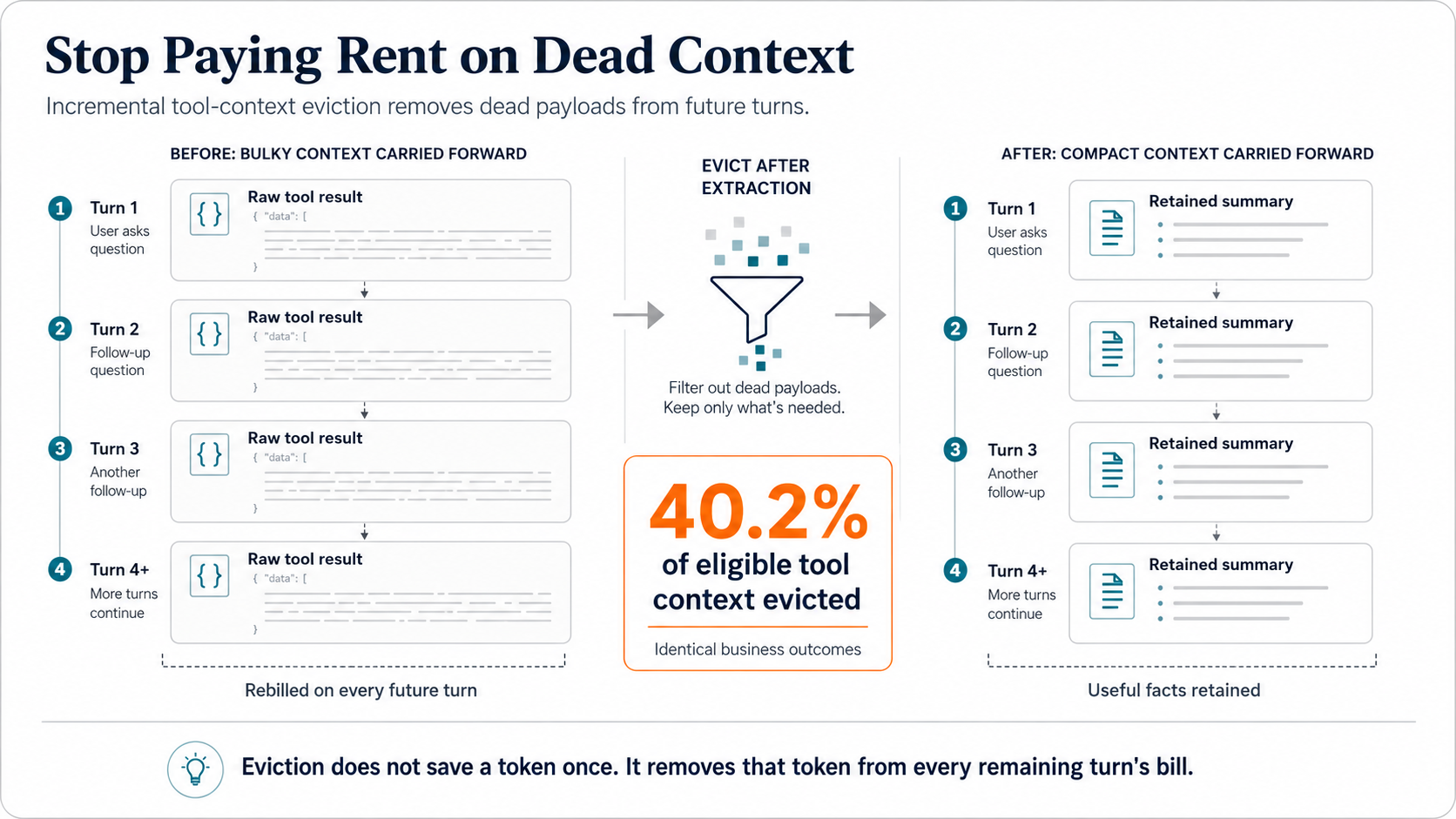
And the arithmetic is even better than it looks. Every evicted token would otherwise have been re-billed on every remaining turn of its conversation. Eviction doesn't save a token once; it strikes that token from every future turn's bill.
Win 2: The Quota Crunch That Lowered Our Bill
Provider agility is usually sold as insurance: something you carry and hope never to use. In our shop, it's a lever we pull for profit.
During a multi-day window in early July, our telemetry flagged rapid consumption and mounting quota pressure on our primary Codex accounts. We didn't wait for a status-page update, and we didn't let a rate-limit error make the decision for us. We shifted the load immediately, routing specific heavy workloads away from premium endpoints to a smaller, highly capable local model: GLM 5.2, running on Ollama.
Over that window, 43.8% of our total token volume ran off-network, and the rerouted tasks came in roughly 47% cheaper than they would have on the premium endpoint. Users never noticed; their workflows ran without interruption. The only thing that changed was the cost profile, instantly and in our favor.
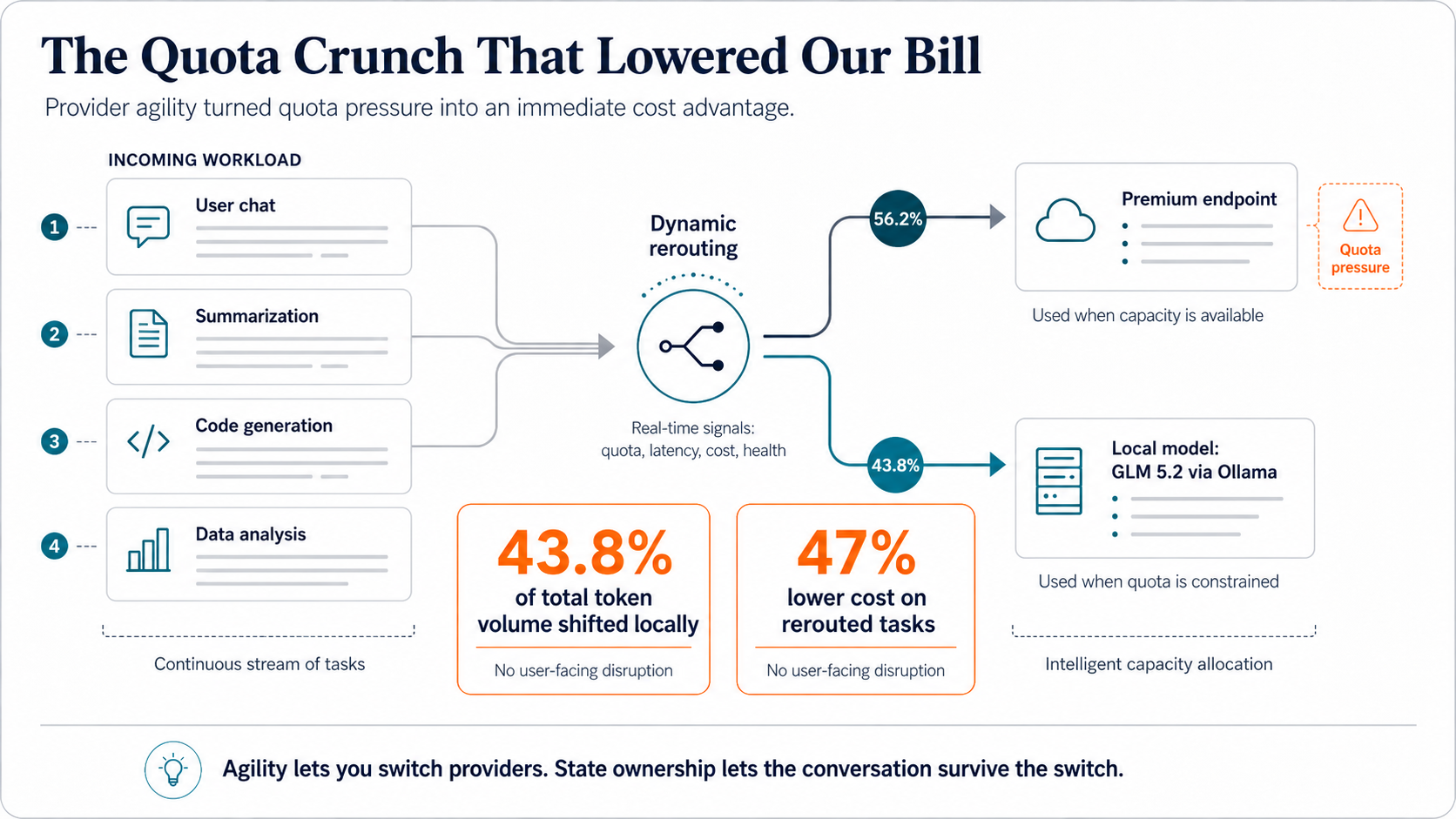
The maneuver works only when the first two pillars hold together. Agility lets you switch providers. Sovereignty means the conversation survives the switch.
Win 3: The Efficiency Upgrade That Wasn't
When OpenAI released GPT 5.6 SOL medium, the launch narrative promised a 15% improvement in token efficiency. The reflexive move, the one most teams made, was to upgrade immediately on the assumption that newer means cheaper.
We took a different path: run both models against our own messy, production-grade agentic workloads and let the data decide. On substantial agent turns, the marketing didn't survive contact with reality:
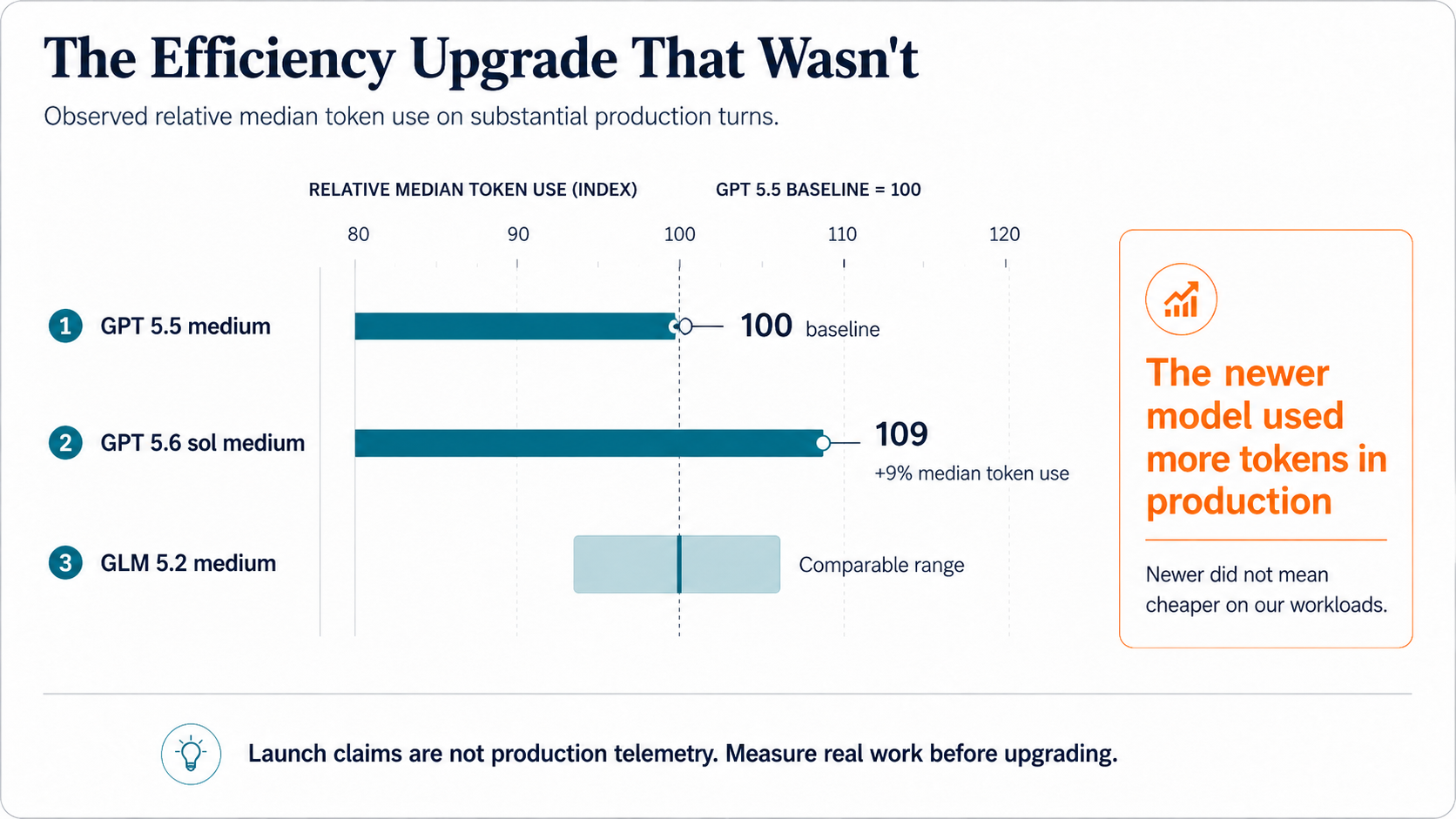
The “more efficient” model consumed roughly 10% more tokens per substantial turn than the one it replaced. Average and median moved in lockstep, so this wasn't a handful of outliers skewing the mean. It was the model's actual behavior on our actual work.
We held the upgrade back from most of our workflows, dodging a cost increase that would never have appeared on any invoice as such. It would simply have shown up as a bill that crept upward for no visible reason.
Why You Can't Trust the Sticker Price
That phrase, a bill that creeps upward for no visible reason, names a frustration heard across the industry: sudden, unexplained token drains that providers routinely deny. Our telemetry suggests those complaints are well founded.
Take provider-native caching, which the market treats as a stable, predictable cost-saver. Within a single observed workload, our measured daily cache hit rates swung from 46.5% to 71.3%. Same workload, same provider, same week, yet the effective price of a token moved by a substantial margin, silently, from one day to the next.
A meter that swings that much isn't a meter. When pricing is this opaque and this non-linear, the only reading you can trust is the one you take yourself.
Build on a Foundation That Measures
Bet your company's AI future on a single provider's API and you inherit their quota caps, their volatile cache rates, and their shifting prices without the instrumentation to see any of it happening.
Partner with Intelligence Factory and you inherit our three pillars instead. Your data stays under your control. Your workflows move freely between labs. Your most repetitive token streams get materialized into deterministic, cost-free code.
Most importantly, you inherit the discipline behind all of it: measure real work, own your state, and stop paying for context the moment it stops helping. Your AI margins should be set by your own meter, not by someone else's marketing.